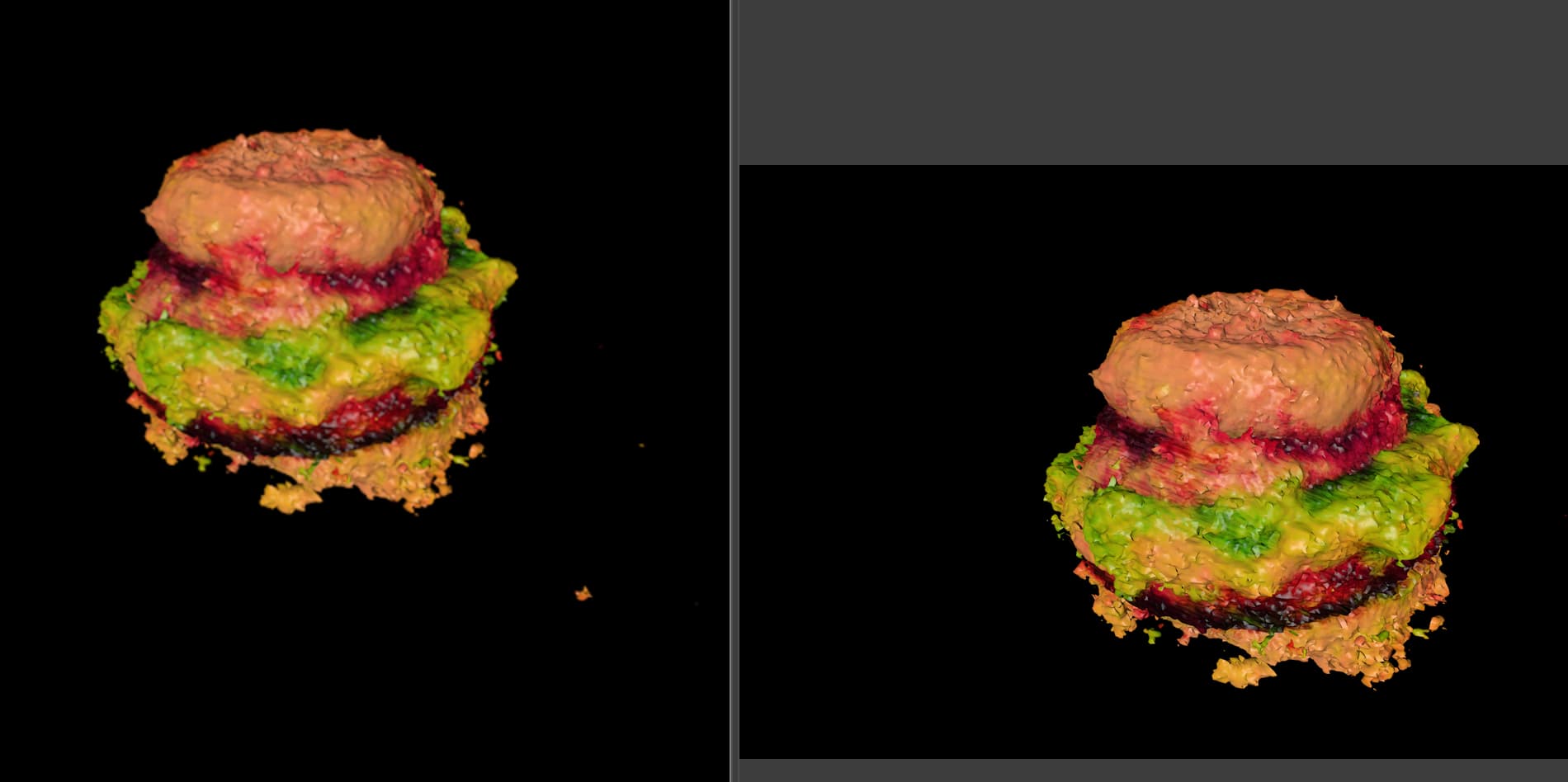apologies for cross posting… I’m looking into this paper now if others are interested…
Another interesting paper… training nerfs from 2d diffusion models…
project page with paper link…
interactive webgl viewers at the bottom…A
apologies for cross posting… I’m looking into this paper now if others are interested…
Another interesting paper… training nerfs from 2d diffusion models…
project page with paper link…
interactive webgl viewers at the bottom…A
Here is a “tiny nerf” colab that I’m looking at to learn more about nerfs…
I was leaving NERFs for later since I can barely keep up with Stable Diffusion ![]() But now I am interested … I’ll pitch in if I can but I have a feeling that I’d be more or less useless
But now I am interested … I’ll pitch in if I can but I have a feeling that I’d be more or less useless ![]()
Would love the company :-)!
#StableDiffusion meets Depth Estimation
Since it seems as if nerf training can be accelerated using Depth Estimation models as a prior in the loss function (or so I’m told). I thought I’d start by mashing up Stable Diffusion with a depth estimation model and toss in my interactive 3D Depth Viewer (three.js) all inside a colab notebook!
This is the same depth viewer from the hugging faces space I did a couple of days ago, but shows the 3D depth viewer inline in a notebook… Much more useful!
Copy the Colab and Play for Yourself!
I tweeted it out here as well if you’d like to give me a like.
Stable Diffusion meets Depth Estimation Tweet
Thanks!
John
OK, going to give this a try a little bit later today but that does sound interesting. I’m curious to see what this does to some of the images that I generate. Good stuff!
@johnrobinsn I took a look at the notebook and can understand what you’re doing now a bit better. Thank you for the notebook! Now, I don’t know a lot about NeRFs except for seeing them on Twitter a lot. My (possibly faulty) understanding was that you could create a 3D scene from just a few images.
So what were you thinking of next in terms of advancing the initial functionality? I had seen something somewhere (possibly an arXiv paper) where you could use SD to get another image (based on a prompt or seed image, I forget which) which would give you a new image from a different angle than the original. Would something like that help with fleshing out the NeRF so that it looks solid when you rotate the scene?
I’m still learning too… But in the initial Nerf implementation the idea was to take in a bunch of images of a single scene, train a neural network on them with a loss function that learns to predict what the scene will look like from any given 3D point in space (and a direction from that point). This gives you a volumetric rendering function that can be used to render the scene (thru something akin to ray tracing). The loss function is to minimize the difference between the different input images and a scene rendered using the learned volumetric rendering model (almost sounds like an autoencoder)… With the goal of generalizing to unseen views of that scene.
Subsequent evolution of the Nerf idea has focused on reducing the number of required image samples (sometimes down to a single reference image but with a lot of learned priors built into the model… things like depth estimation models for example) and some variants replacing the neural network bit with a different differentiable data structure that is more efficient to render/train.
The main idea in the DreamFusion3D paper is to use diffusion models (2D) like the one we’ve been playing with to act as a prior and a training signal to learn Nerf (3D) models of objects by just using text prompts. I’m pretty much looking to replicate the paper results for now (Try out the interactive 3D objects at the bottom of the project page… that’s the ultimate goal).
I probably need to read the DreamFusion3D paper a few more times and better understand the training flow interaction between the nerf bits and the stable diffusion bits… while still learning both ![]()
Maybe we could get together to understand the paper a bit deeper together and go thru the mathy bits in a couple of days after we’ve been able to digest the paper more? Let me know…
Code experiment-wise… I think I’m going to try and go thru the “tiny nerf” colab (that I shared above) and create a few notebooks of my own to experiment with some ideas and to get a deeper understanding.
Thanks.
Thank you for the explanation ![]() I should have read the paper again before asking questions.
I should have read the paper again before asking questions.
Yes, I’d be up for going over the paper together in a couple of days. I think I missed the tiny NeRF colab the first time around somehow. I’ll try it too and see what I learn. Will let you know.
@javismiles and I stumbled on the this fresh baked (stable diffusion) implementation of the DreamFusion3D paper…
It was easy enough to get it to build…
Now training, training training…
yes yes, thats the same one I knew, its the one that says
" This project is a work-in-progress , and contains lots of differences from the paper. Also, many features are still not implemented now. The current generation quality cannot match the results from the original paper, and many prompts still fail badly!"
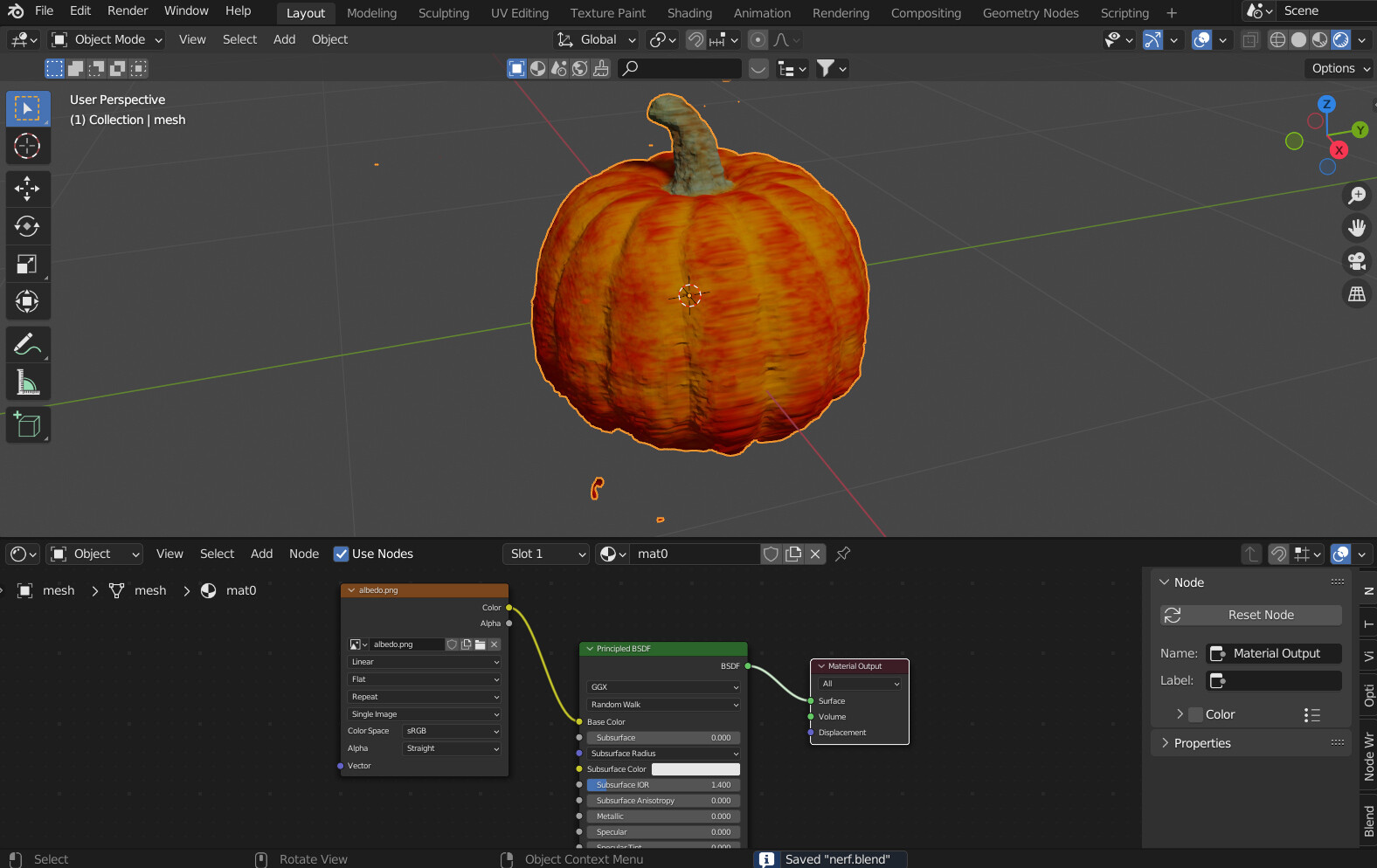
Using ashawkey’s stable-dreamfusion repo, I rendered a 3D pumpkin from a prompt “A pumpkin” (heh)… pretty cool! Not gorgeous but a good starting point to iterate from.
I took a little video and tweeted it if you’d like to see the output that I got after about 30 minutes of training…
In it’s current form definitely works better with objects that have radial symmetry (pineapple, pumpkin etc). I tried teddy bear but in its current form suffers from the “janus” problem… making an object that had a face on both the front and back… and duplicate arms/legs. I think I have ideas on how to fix that that I’ll probably give a try over the weekend.
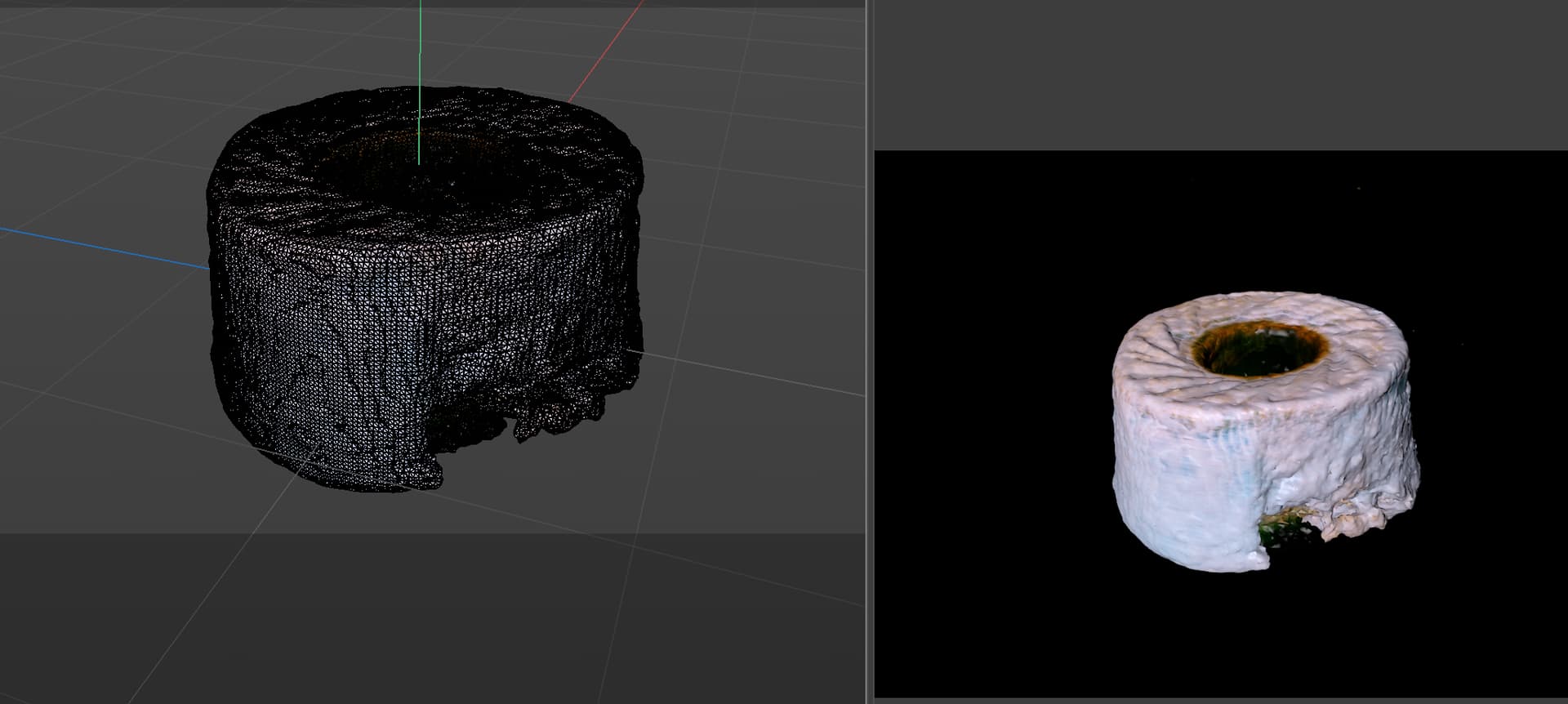
I’ve played with this too and was a little disappointed with the results (rubber duck, toilet paper roll, hamburger below.)
But it is a cool exercise in “fusion” of NeRF, depth map estimation, and txt2img – I’d be keen to understand + be fluent in mixing and matching these approaches. (Fun historical note: check out this comment from mere days before the release the paper. GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images | Hacker News)
Meanwhile I’d like to explore what’s going on in 3d diffusion – Voxel diffusion seems straightforward with a direct analogy to pixel diffusion. ShapeNet offers voxelizations of many (>1000) classes, and you could always voxelize 3d objects yourself if you gathered a dataset…if anyone knows exciting work in this direction, LMK, otherwise I’ll wade in.
I wonder if diffusion can be applied to generative NeRFing.
Y. The dreamfusion examples from the paper seem to be much better. The GitHub author admits irs early days on this impl.
yes, still early days, the quality of the mesh provided by the marching cubes alg is just not good at all, but things could evolve rapidly in this field, crossing fingers, this is all very exciting
I ran the pumpkin one overnight (8 hours) just to see where it ended up… started picking up a jackolantern vibe.
Hi John,
Would love to join you in this exploration. I shall DM you on Twitter!
Hi John,
Tried to DM you on Twitter but couldn’t. Can you please write to me at https://twitter.com/tweetvbaskaran or please drop me an email at vignesh.sbaskaran@gmail.com. We can carry on from there. Thank you
I started keeping a few notes in a google doc on the ashawkey repo codebase.
request access there if you’d like to contribute…
You can enable a camera pose visualization for example.
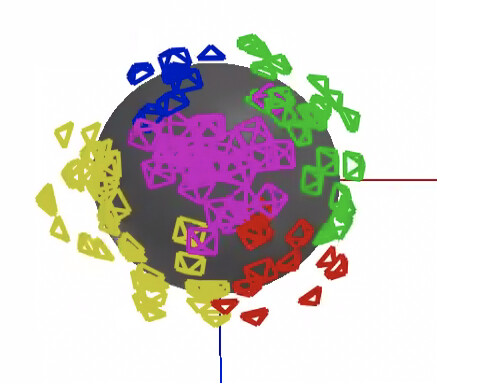
The same person has another repo for a pytorch implementation of instant ngp (without the Stable Diffusion bits) so you can more easily see what’s been added in for the stable diffusion variant.
Using this I did a nerf of the classic lego bulldozer… (from 50 static images) here…

Some nerf wonkiness even here… but perhaps demonstrates the envelope of what might be possible if we can coax good images from Stable Diffusion (given context etc).
translating the nerf to better quality meshes is a separable challenge…