I have the same issue. There is an double “[0]” in sgdr.py:79
If you change it to single, it will work correctly.
But anyway I think there should be a conditional loop through vals, to support multiple or single val losses,
.fit(…, all_val=True) will pass here multi val losses.
This isn’t what happens. No data augmentation occurs when precompute=True. Search the forums for “precompute” to see the correct answer to this question.
I try to use .fit(…, all_val=True),another issue came up.
I change the source code a lit by add some if/else to avoid the scalar vals[0] to be indexed.
thank you very much for you answer.
Unless the training loss is above or equal to validation loss there is no overfitting, however if your validation loss starts increasing above your training loss, it is cause of overfitting.
Could you please explain why this process of precomputing the activations is not used with the transformed versions of the image?
Why would you not want to precompute the activations of the transformed images? Is that because they are random and the precomputed activations won’t be useful when a new random transformation is used in a next training?
This is an awesome tip, but I’m not understanding the novelty aspect. How does it differ in any way from augmenting with zoomed images, what we learned to do previously? Conceptually it isn’t any different. Is there something different under the hood going on?
01:32:45 Undocumented Pro-Tip from Jeremy: train on a small size, then use ‘learn.set_data()’ with a larger data set (like 299 over 224 pixels)
I looked some more and the zoom actually is cropping. So that’s the only difference, right? If it were a non-cropping zoom, there would be no difference in these approaches?
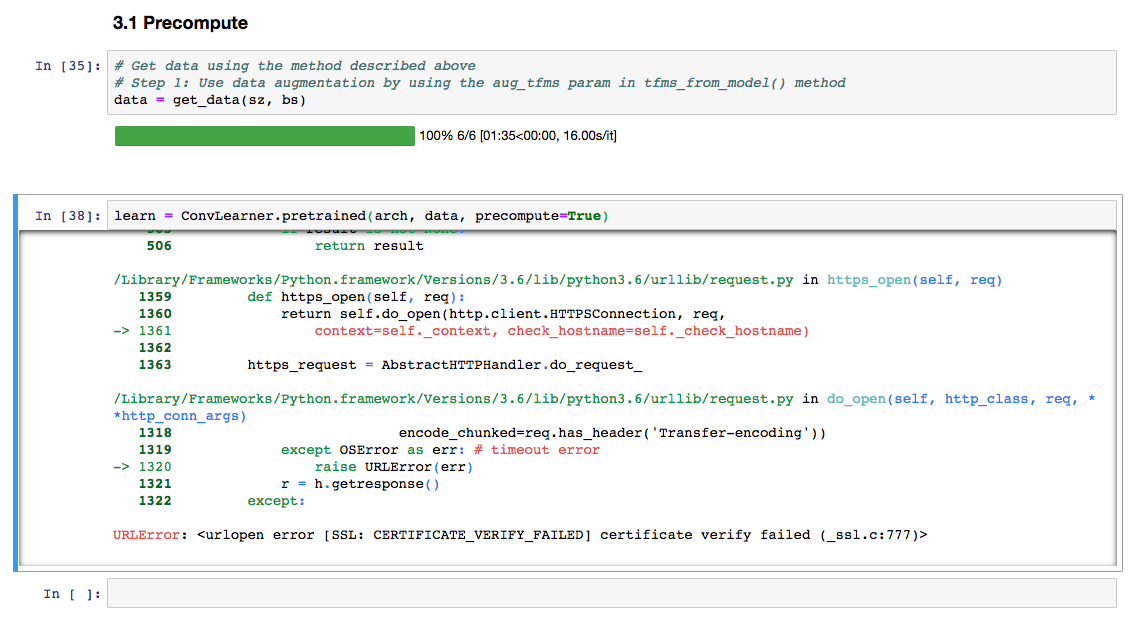
I’m trying to perform dog breed image classification on my laptop and I’m getting the below issue. Looks like its because the site has bad SSL implementation. This issue occurs while trying to download resnet from pytorch website.
Any ideas on how to resolve this issue would be appreciated.
I’ve been playing around building a model with the dog breeds competition, following the same steps as in lesson 2.
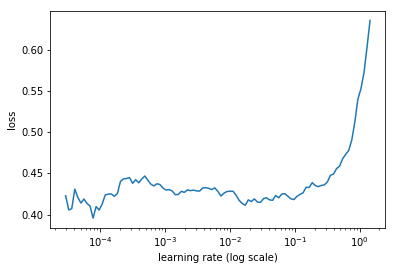
After changing the image size from 224 to 299, I decided to rerun the lr finder, and get something like this:
I didn’t really pay attention to the graph at first and kept the lr at 1e-1 and got some improvement.
Make me wonder if the lr finder graph is very helpful in this case? How would you pick the lr with this graph? I guess we do have a downward slope from 5e-4 to 1e-1.
Would a lr finder graph showing val_loss vs lr, or accuracy vs lr be more insightful? I would be curious to know what that looks like. Are those options available in the fastai library?
Also wondering if a lr finder graph showing rate of change of loss vs lr might be bring some additional insights.
Hi,
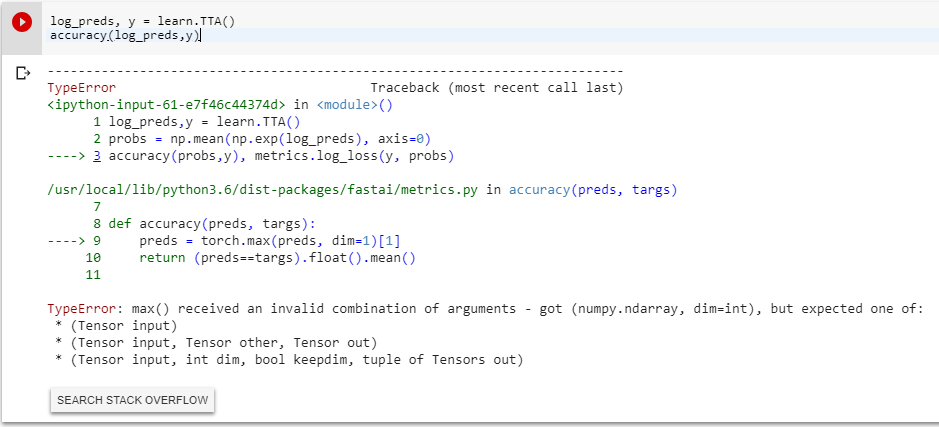
After running the TTA () library, I get an error when I print the percentage of success to the screen. I can not find the mistake. I will be glad if you help me.
Can’t find packages to install p7zip when using a Paperspace Gradient notebook (haven’t gotten an instance after more than two weeks of waiting so can’t use that route) so couldn’t get further than downloading the archived files.
I ended up using an Amazon SageMaker instance, and could install p7zip to unarchive the files using the following commands;
sudo yum install p7zip
7za x -so train-jpg.tar.7z | tar xf - -C .
7za x -so test-jpg.tar.7z | tar xf - -C .
I set up a Gradient account on Paperspace, and imported the Fast.AI notebook for the course. Lesson 2 does not work by default, as it is missing the Planet dataset; there do not appear to be instructions in the notebook as to how to import the dataset. What’s the easiest way to import the data?
Answered my own question by searching the Wiki, a lovely walkthrough written bt daphn3cor. Perfect for learning how to install files under the Gradient Jupyter notebook on Paperspace.
Thank you for spending time to provide this for newcomers; I would have gotten stuck without this information.
How does batch size impact image augmentation and model performance? My understanding is that in one epoch with augmentation, the network is trained on one augmented version of each image in the dataset. Batch size affects the number of iterations/weight updates within an epoch. Larger batch sizes require more epochs to converge because each epoch has fewer weight updates compared to epochs with smaller batch sizes.
If I use a large batch size, does that mean the network is seeing more images per weight update? In the context of using image augmentation to expand a limited dataset, would a higher batch size be advantageous because the network would see more augmented versions of images over the course of the training process?
My guess is that you started from an already trained model. Thus you don’t see any decline in loss. As I understand it, for lr_find() to work, you’ll have to start from untrained (or only slightly trained) model.
Question about Lesson 1 task: test/validation score and accuracy given in Lesson 2 video
I have a problem understanding why training loss is bigger than validation loss function (see 4:13 in the video of lesson 2). As far as my understanding goes, training loss will almost always be smaller than validation loss (if we don’t count occasional lucky chance). After all, training data is what we see.
Second question is about accuracy we can get. Please take a look at accuracy of the model with augmentation at 25:44 in the video of lesson 2. The value of 0.936 is quite high and I would like to hear about accuracy you get at this point. If I run this few lines of code multiple times, I get accuracy all over the place, so is this the reason for quite high accuracy in the video?
I know one of the method for getting better model is to retrain the model from different starting position, so this might be one reason. Quite oddly, I get somewhat different histogram if I don’t remove folders models and tmp (although this is a subjective conclusion, with 100 runs only).