You can find @jeremy 's comment in this thread.
Thanks. I checked it.
I understand either resnet34 might not be a good model for this or imagenet might not be good image data for this. Anyways, I tried to change batch size parameter in ImageClassifierData.from_paths and it gave relatively logical loss vs. learning rate curve. So default batch size of 64 was not good for my data, probably because my train data was not large enough and learning rate finder stopped in less iterations.
See below –
Few questions about our process:
Highlighted in bold against each point
- Enable data augmentation, and precompute=True Why are we saying enable data augmentation here? Doesn’t data augmentation starts at step 4?
- Use lr_find() to find highest learning rate where loss is still clearly improving
- Train last layer from precomputed activations for 1-2 epochs Does it always have to 1-2 epochs or we shall try more?
- Train last layer with data augmentation (i.e. precompute=False) for 2-3 epochs with cycle_len=1
- Unfreeze all layers
- Set earlier layers to 3x-10x lower learning rate than next higher layer
- Use lr_find() again Do we create new learn object or find lr for learn which has already learnt a lot in step3, 4?
- Train full network with cycle_mult=2 until over-fitting
For point 7.
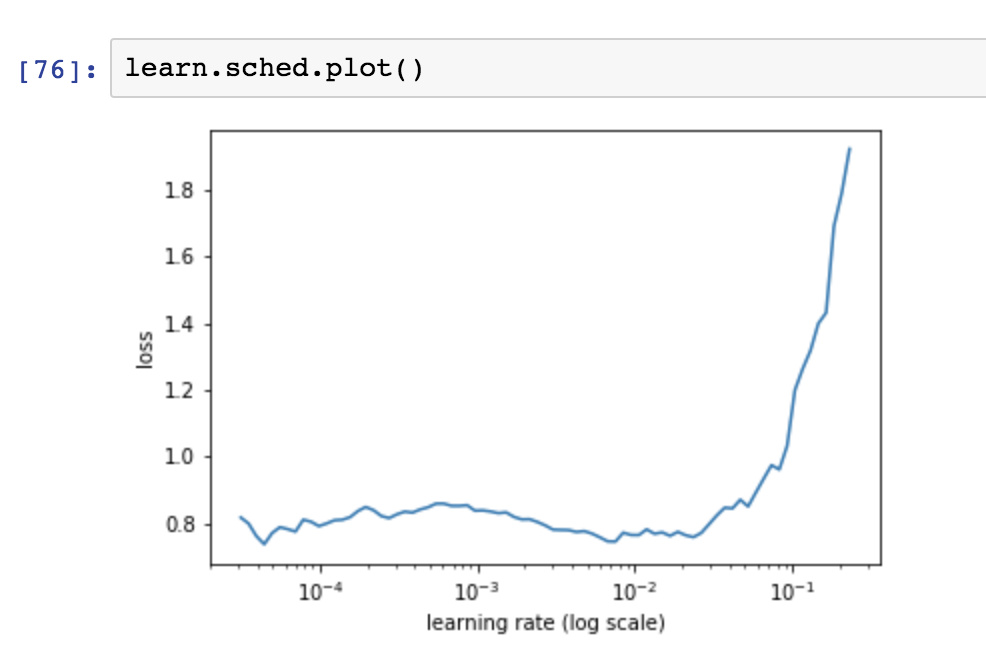
When I try with new learn object, lr curve is
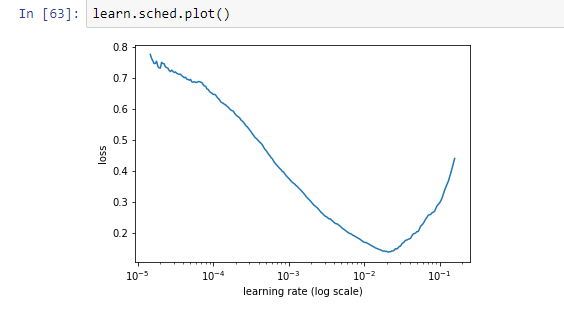
But when I try with learn object which has learnt in step3, 4.
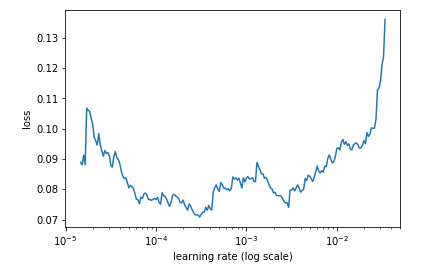
How do I depict and see I should change my lr?
3 Likes
Fine tunning with differential learning rate:
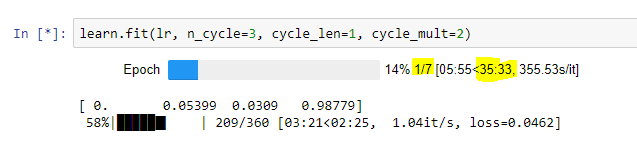
Is it normal for p2.xlrge to take 40 minutes for 7 epochs?
1 Like
Why differential learning rate fuactuates so much and provide less accuracy for me?
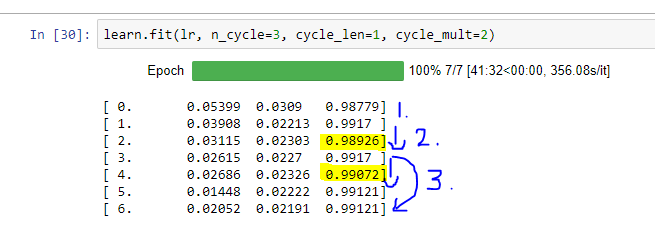
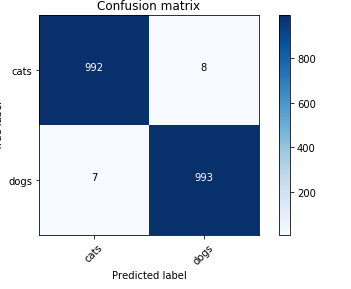
Overall accuracy is 99.29 than 99.65 of Jeremy’s. Is it by chance or?
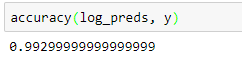
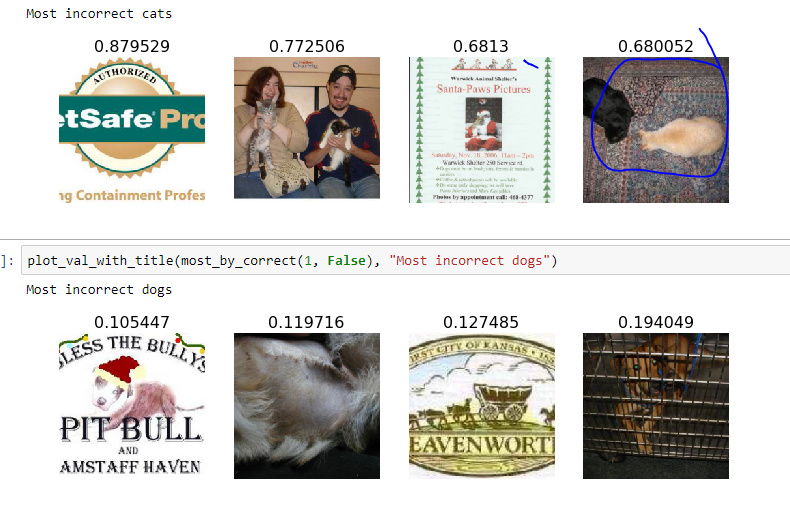
Overall 14 wrong predictions:
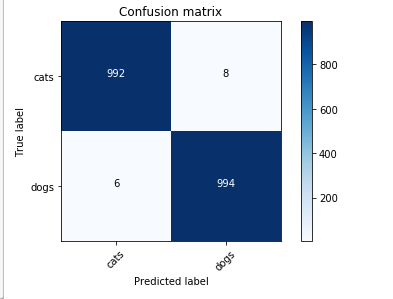
Different cases:
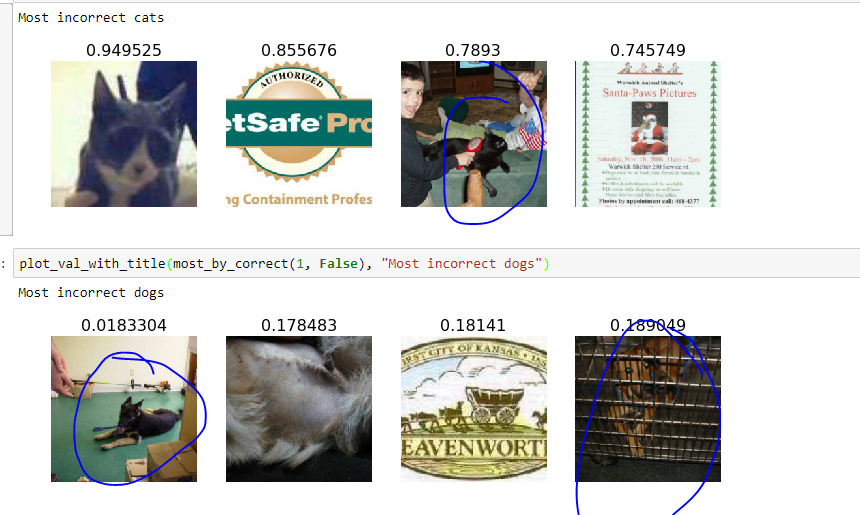
When I restarted kernel and loaded saved weights, instead of 14, I had 15 wrong predictions

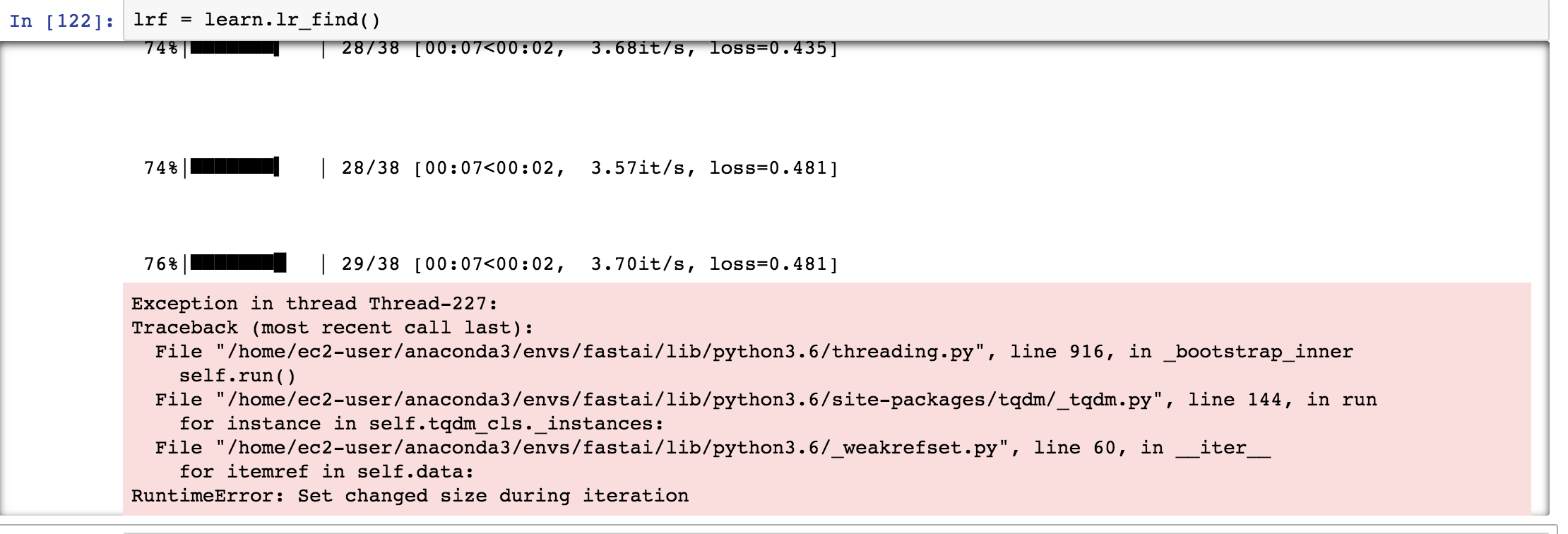
When I try to use lr_find, why does it randomly gives RuntimeError: Set changed size during iteration error sometimes?
Image –
2 Likes
I too got this while I was jumping between steps. If you try to run code sequentially:
- create data object
- Create learn
and then try… it should work fine.
BTW, I’m curious about multiple loading and error too.
mm… Ok. A follow up question then. I ran code sequentially, but what I did was the following.
After creating the learn, I plotted the loss vs. iteration using plot_loss(), it showed a good declining graph. So, I thought I could reduce loss more by running same code again or by using more epochs. For that I tried to check updated learning rate using lr_find. That’s when I encountered this error.
Any comments on this?
1) I guess even though precompute is True at step enabling data augmentation has to do with tfms in data construction step.
3) So for pretrained networks we have 4 possible situations:
- We have large amount of data and data is similar to pretrained network's data.
- We have large amount of data and data is not similar to pretrained network's data.
- We have small amount of data and data is similar to pretrained network's data.
- We have small amount of data and data is not similar to pretrained network's data.
For each case we basically want to have different strategies to tackle the problem.
For first case it’s very easy just tuning last layer (final FC) for 1-2 epochs is enough. As we saw this in lesson 1 with cats and dogs, even after tweaking a litlle accuracy was almost perfect.
For second case we again start with tweaking the last layer but we also want to take advantage of our large amount of data and might want to change a couple of more layers in our FC layers. I guess we can consider this stage as unfreezing the rest of the FC layers.
For third case again starting with tweaking the final layer but maybe this time a lot more data augmentation is needed since we don’t have enough data. But good part is that our data is similar to what the network was trained on so it will still capture many valuable features (convolutional part - edges, colors, …).
This final case is a lot similar to iceberg challenge, where you need to be a lot creative, but still as you can see all 4 cases can be answered by pretrained networks which makes transfer learning a very powerful technique in that sense.
To answer the question, I think no matter which situation you are facing starting with 1-2 epochs and tweaking your final FC layer is the right way to go. Even the rest of steps will be similar more or less for every case but with different approaches or different reocurrences of steps. I think it’s more of an iterative step which is why they say it’s like babysitting 
7) No, you shouldn’t create a new learn object because if you do it will give you the same best lr that you found to begin with. Idea of calling lr_find() is to find the best lr for you current optimization process after you have changed the weights by previous steps.
I think these are great questions by the way. I tried to answer them with the little experience I 've gained through the past 2 weeks, so it’s better to wait for @jeremy and learn more and correctly about it.
Hope that I helped even a little
Edit: I found this, which can also be helpful to understand the intuition and when/where for pretrained networks, https://www.analyticsvidhya.com/blog/2017/06/transfer-learning-the-art-of-fine-tuning-a-pre-trained-model/
It is also amazing that 50% of the research on deep learning involve pretrained networks at some point. No wonder why we also start with it in this course.
Best
7 Likes
Thank you.
For point 1, Jeremy mentioned that data augmention doesn’t work with precompute=True. Any thoughts?
For point 7, how would your depict the LR in such case? Please check snapshots in original query.
For point 1. Yes, because precompute=True precomputes the activations for speed, but if you want data augmentation which happens on the fly you should let it calculate activations by doing forward pass during fit (combines forward pass backward and grad updates) hence set precompute = False to use data augmentation. The reason that augmentation wouldn’t work I guess is an implementation thing, since activations are ready and computed for speed issues it will pass couple of initial steps.
For point 7, I would go for lr = 1e-4.
Thank you.
For point 1, I was saying that while precompute is true data augmention won’t work so why do we’ve data augmention mentioned in step1 of 7 step process?
For point 7, Jeremy mentioned that he skipped lr finder because it didn’t help. Is it because <1e-4 is too slow and will take huge time to find minima? He chose 1e-2 which clearly is on side which isn’t recommended.
Have you tried finding lr at this step?
What you are seeing is not that much about the differential learning rate but the cyclical learning rates. Every few iterations (epochs) you are increasing the learning rate and then decreasing again. This makes the accuracy jump to a slightly worst state.
Note that 0.993 and 0.996 are very small differences in terms of the number of samples that you get wrong.
Great questions!
Yes that’s true. Although if you set it at the start, you don’t have to change anything later - data augmentation is silently ignored until precompute=False.
There is a risk of overfitting here, so I’d suggest not doing more than 1-2 epochs without augmentation.
Use the existing object - the point is to see whether the weights at this point, along with the unfreeze and differential learning rates, result in a different optimal learning rate. That’s why the LR finding curve looks very different at this point - it’s much harder to improve the loss at this point.
1 Like
Is that what I said? I’m not sure that’s quite what I meant to say! I’d looked at this dataset a few times and found that leaving LR at that level seemed to work OK, so didn’t bother with lr_find again. But it’s probably a good idea for when you’re first working with a dataset.
The lr_find graph you show is interesting. It certainly shows that 1e-2 is on the high side - although I did want an LR which would help it jump out of ‘spikey’ parts of the loss function, and I was finding otherwise that I tended to overfit at this point.
1 Like
It’s just a warning - you can ignore it.
1 Like
Thanks @jeremy.
For point 3, if we get curve like shows in original question, do we ignore it or is there a way gain more insight about it?
- The curve isn’t smooth so if we were to find optimal value of lr, do we consider sharp increase and decrease?
- The values of lr itself are too small
Some variation is expected, although 99.1% is lower than I’ve seen in my testing. Might be worth checking you’re going through all the correct steps.
Yup! 99.65 and 99.1 has significant difference. I’ll rerun everything in default notebook and check the results.
The above result is from notebook I wrote after going through code so I may have skipped overlapping steps.