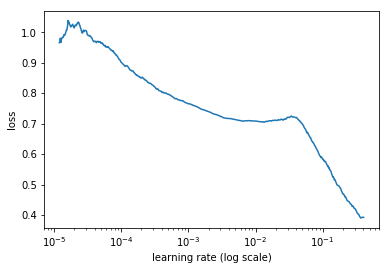
If I fit the model with 0.1 learning rate my BCE with logits loss goes to nan but the loss decreases amazingly fast! Could this be super-convergence?
The training is stable with 0.001 learning rate. I read somewhere that the nan loss could be because of too high learning rates. Maybe I am getting it because of that but it would be cool to find a way to train with 0.1 or higher learning rates.
