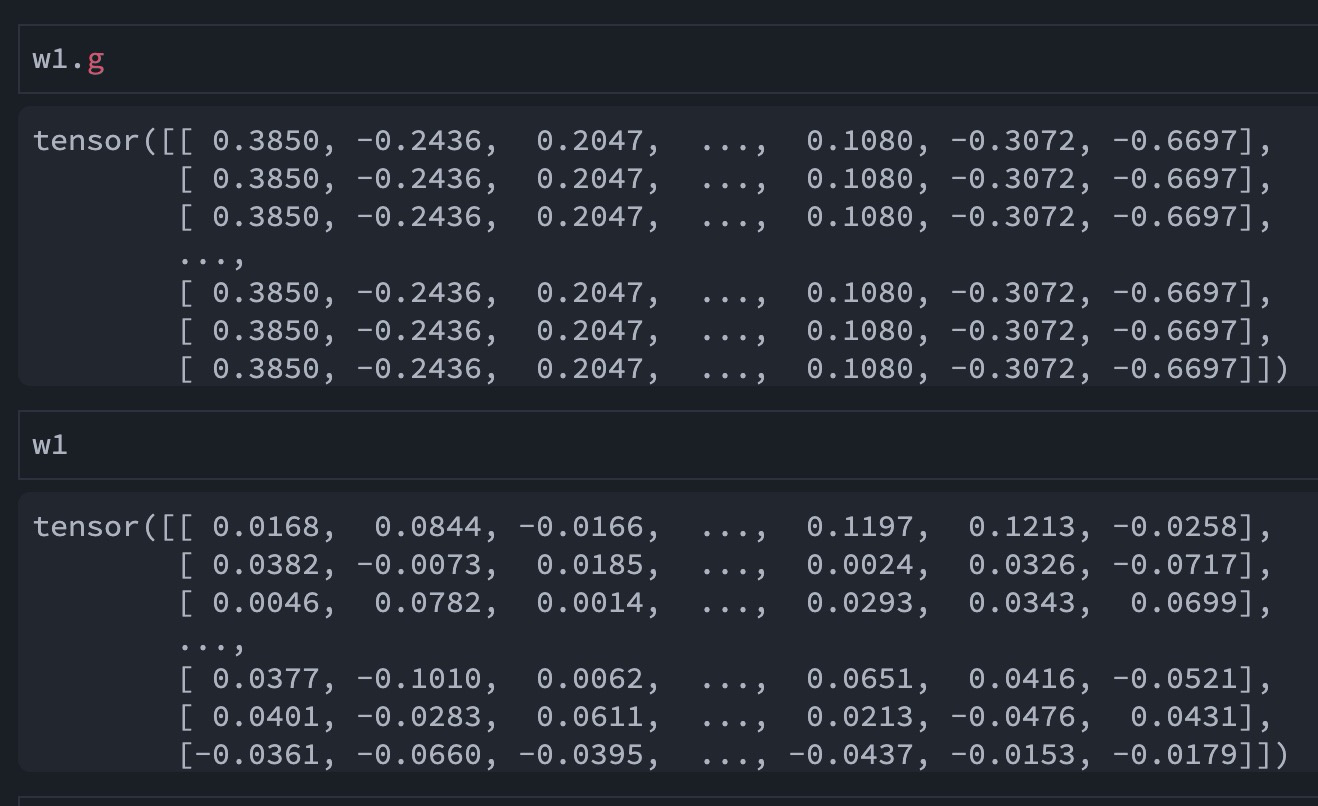
“Wait what?! thats a vector !” “That means we are scaling complete rows of the weigth matrix by the same value?!”
(well I did not phrased it like this at the time, I just paused the video and froze for a moment)
Since the beguinning I thought grads were processed for each and every value in the weight matrix and they were all corrected independantly.
Does this would even make sense?
Would this be far too much computation?
This certainly would be far more difficult to train… is it?
One thing is certain:
I really should take Rachel’s Linear Algebra course
Not only w but also all other quantities here (inp, out and out.g) are matrices!
Their first dimension is the batch_size (or in this case the whole dataset size) and that’s actually the dimension you’re summing over!
So when you do .unsqueeze(-1) on inp you get a 3D tensor and when you .sum(0) you get back to a matrix, with one element for each w element and you’re simply summing all the gradients coming from all samples!
TLDR, yes they are matrices, so you’re indeed computing gradients for each and every value of w!
(you could add a few print statements in the lin_grad function to check what’s going on in case of doubts!)
I think that’s correct, in particular the images are flattened in that example and some of the initial / final pixels for every sample will always be black as they correspond to the corners…
The center part of the image should have different elements though, if everything is being processed correctly!