walkthru 9: a note in the form of questions
thread
Installing timm persistently in Paperspace
01:00
What’s inside Jeremy’s .bash.local at the beginning of walkthru 9
#!usr/bin/env bash
export PATH=~/conda/bin:$PATH
How and where to create alias for pip install -U --user
vim /storage/.bash.local
alias pi="pip install -U --user"
source /storage/.bash.local
How to print out the content of an alias?
type pi
How to install TIMM on paperspace?
pi timm
How to check whether TIMM is installed into your home directory’s .local?
ls ~/.local/python3.7/site-packages/
How to create a file in terminal without any editting?
touch /storage/.gitconfig
How to check the content of a file in terminal without entering the file?
cat /storage/.gitconfig
How to apply /storage/pre-run.sh after some changes?
source /storage/pre-run.sh
What’s wrong with the symlink .gitconfig -> /storage/.gitconfig/?
05:24
you accidently symlink a folder to a file
How to run ipython with a shortcut?
just type !ipy as long as you typed it before
How to run ctags properly for fastai/fastai?
fastai/fastai# ctags -R .
vim tricks moving back and forth in previous locations
08:39
ctrl + o move to previous places
ctrl + i move to next places
vim: jump to specific place within a line using f or F
10:23
f": jump to the next " in the line after the cursor
fs: jump to the next s in the line after the cursor
3fn: jump to the third n after the cursor in the line
shift + f + s: jump to the first s before the cursor in the line
vim: delete from cursor to the next or previous symbol or character in a line
dFs: delete from cursor to the previous s
df": delete from cursor to the next "
/" + enter + .: search and find the next " and redo df"
vim: moving cursor between two (, ) or [, ] or {, } and delete everything from cursor to the end bracket using %
11:24
%: toggle positions between starting and ending bracket
d%: delete from cursor to the end bracket
df(: delete from cursor to the first (
vim: delete everything within a bracket with i
12:19
di(: delete everything within () in which cursor is also located
di{: delete everything within {} in which cursor is also located
vim: delete content within () and enter edit mode to make some changes and apply it all (including changes) to next place using ci( and .
12:59
ci(: delete everything between () where cursor is located and enter the edit mode to make changes
move to a different position within a () and press .: to redo the action above
Why and how to install a stable and updated dev version of TIMM
14:03
What is pre-release version?
pi "timm>=0.6.2dev"
How to ensure we have the latest version?
“timm>=0.6.2dev”
How to avoid the problem of not finding timm after importing it?
16:06
use pip install --user and then symlink it from /storage/.local
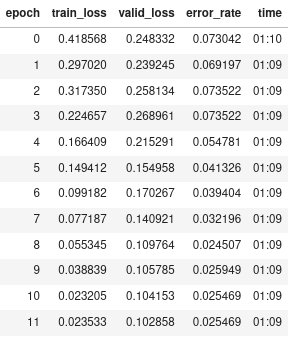
Improve the model by more epochs with augmentations
a notebook which trained longer with augmentations beat the original model we have
How many epochs may get your model overfitting? and why? and how to avoid it
18:39
The details is discussed in fastbook
Explore aug_transforms - improve your model by augementations
19:34
Read its docs
Read what is returned
How to display the transformed pictures with show_batch?
dls.train.show_batch(max_n=4, nrows=1, unique=True)?
This is how aug_transforms ensure model not see the same picture 10 times when training for 10 epochs
Improve your model with a better pre-trained model
21:52
Improve your model with a better learning rate
22:09
Why the default learning rate of fastai is more conservative/lower than we need? to always be able to train
What are the downsides of using lower learning rate
22:31
weights have to move in less distance with lower learning rate
higher learning rates can help jump further to explore more or better weights spaces
How to find a more promising learning rate?
23:04
How to read and find a more aggressive/appropriate learning rate from lr_find to
How to export and save your trained model?
24:21
Explore learn.export
Where does learn.export save model weights by default?
How do we change the directory for saving models?
learn.path = Path('an-absolute-directory-such-as-paddy-folder-in-home-directory')
Explore learn.save
How does learn.save differ from learn.export?
What does learn contain in itself? model, transformations, dataloaders
When to use learn.save over learn.export?
27:22
when need to save model at each epoch, and load the updated model to create a new learner
Which data format is used for saving models? pkl
Explore min_scale=0.75 of aug_transforms and method="squish" of resize: improve your model with augmentations?
28:42
Why Jeremy choose 12 epochs for training?
30:15
Why Jeremy choose 480 for resize and 224 for aug_transforms
31:00
details on resize can be found in fastbook
Why Jeremy pick the model convnext_small_in22k with emphasis on in22k?
32:06
What does in22k mean?
How is this more useful to our purpose? or why Jeremy adviced to always pick in22k models?
Will learn.path for saving models take both string and Path in the future?
33:14
Test-time augmentation and what problems does it solve
34:04
What is the problem when we don’t use squish? only take images from the center, not the whole image
Another problem is that we don’t apply any of those augmentations to validation set. (but why this is a problem? #question )
Test-time augmentation is particularly useful when no squish is used, and still useful even with squish.
What is Test-time augmentation? It is to create 4 augmented images for each test image and take average of predictions of them.
How to calculate/replicate the model’s latest error-rate from learn.get_preds?
35:25
Explore Test-time augmentation (tta)
36:21
Read the doc
How should we learn to read the source code of learn.tta guided by Jeremy?
Let’s run learn.tta on the validation set to see whether error-rate is even better
How many times in total does learn.tta make predictions? 5 = 4 augmented images + 1 original image
How do Jeremy generally use learn.tta? He will not use squish and use learn.tta(..., use_max=True) 39:21
How to apply learn.tta to test set and work around without with_decoded=True in learn.tta?
39:38
How to find out the idx of the maximum prob of each prediction with argmax?
How to create idxs into a pd.Series and vocab into a dictionary and map idxs with dictionary to get the result?
How to create dictionary with a tuple?
42:22
Good things to do before submission
45:09
Why to compare the new results with previous results? to make sure we are not totally breaking things.
Also to document the codes of previous version just in case we may need it later
Please make detailed submit comment to specify the changes of this updated model
Check where we are in the leader board
How to create the third model without squish but with learn.tta(..., use_max=True)?
49:02
How to create the fourth model using rectangule images in augmentation?
51:05
How to the original image’s aspect ratio but shrink the size?
When to use rectangule rather than square images in augmentation?
How to check the augmented images after changing the augmentation settings?
Why and how to adjust (affine_transform) p_affine?
54:40
What does affine transformation do? zoom in, rotate, etc
if the augmented images are still in good resolution, then we should not do p_affine that often, so reduce its value from 0.75 to 0.5
Save your ensemble/multiple models in /notebooks/s on paperspace
56:12
Why or when to focus on augmentation vs different models?
57:24
Please feel free to join walkthru
1:00:34
jupyter: How to merge jupyter cells?
shift + m