@jeremy
sure… i know i encounter the same symptom at two different locations: both during loading, and during the fitting. But let me try show you that. Give me around 15 min. of time though.
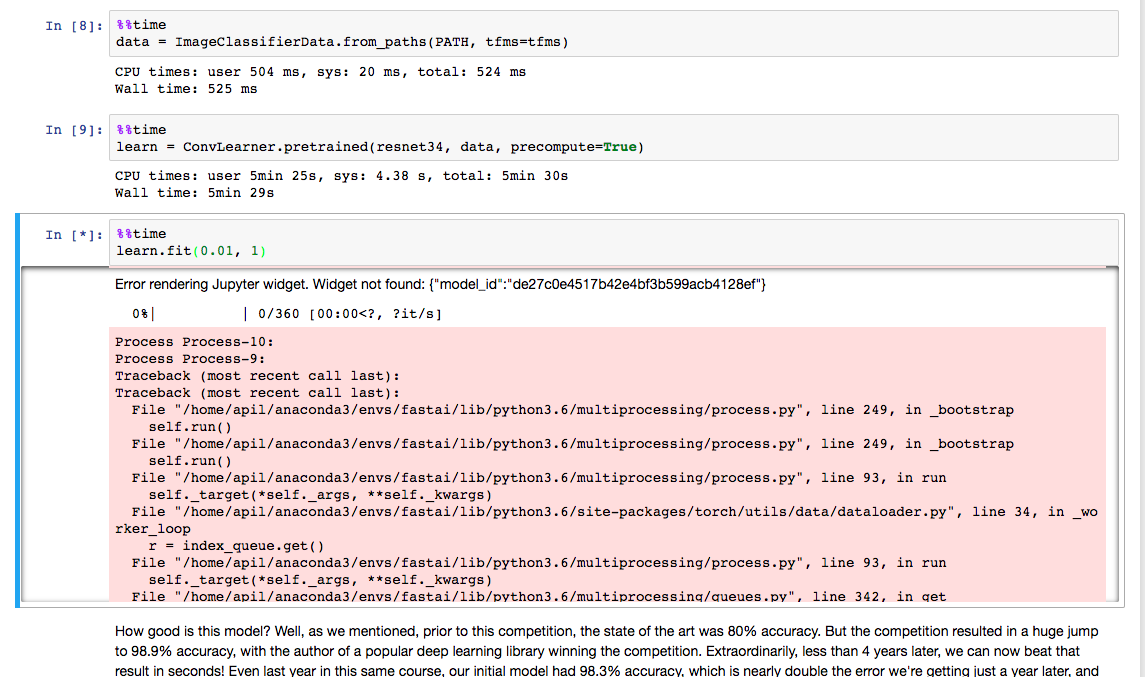
here’s a screenshot of it failing. The stacktrace is pretty deep… so I have it attached in a different text file:
1. Screenshot of ipython notebook
2: Text dump of entire stacktrace
Process Process-10:
Process Process-9:
Traceback (most recent call last):
Traceback (most recent call last):
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 249, in _bootstrap
self.run()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 249, in _bootstrap
self.run()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 93, in run
self._target(*self._args, **self._kwargs)
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 34, in _worker_loop
r = index_queue.get()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 93, in run
self._target(*self._args, **self._kwargs)
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/queues.py”, line 342, in get
res = self._reader.recv_bytes()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 34, in _worker_loop
r = index_queue.get()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/connection.py”, line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/queues.py”, line 341, in get
with self._rlock:
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/connection.py”, line 407, in _recv_bytes
buf = self._recv(4)
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/connection.py”, line 379, in _recv
chunk = read(handle, remaining)
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/synchronize.py”, line 96, in enter
return self._semlock.enter()
KeyboardInterrupt
KeyboardInterrupt
Process Process-12:
Process Process-13:
Process Process-11:
Traceback (most recent call last):
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 249, in _bootstrap
self.run()
Process Process-15:
Process Process-14:
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 93, in run
self._target(*self._args, **self._kwargs)
Traceback (most recent call last):
Traceback (most recent call last):
Traceback (most recent call last):
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 34, in _worker_loop
r = index_queue.get()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 249, in _bootstrap
self.run()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 249, in _bootstrap
self.run()
Traceback (most recent call last):
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 249, in _bootstrap
self.run()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 93, in run
self._target(*self._args, **self._kwargs)
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 93, in run
self._target(*self._args, **self._kwargs)
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 93, in run
self._target(*self._args, **self._kwargs)
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/queues.py”, line 341, in get
with self._rlock:
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 249, in _bootstrap
self.run()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 34, in _worker_loop
r = index_queue.get()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 34, in _worker_loop
r = index_queue.get()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 34, in _worker_loop
r = index_queue.get()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 93, in run
self._target(*self._args, **self._kwargs)
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/queues.py”, line 341, in get
with self._rlock:
Process Process-16:
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/synchronize.py”, line 96, in enter
return self._semlock.enter()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/queues.py”, line 341, in get
with self._rlock:
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 34, in _worker_loop
r = index_queue.get()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/queues.py”, line 341, in get
with self._rlock:
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/synchronize.py”, line 96, in enter
return self._semlock.enter()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/synchronize.py”, line 96, in enter
return self._semlock.enter()
Traceback (most recent call last):
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/synchronize.py”, line 96, in enter
return self._semlock.enter()
KeyboardInterrupt
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 249, in _bootstrap
self.run()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/queues.py”, line 341, in get
with self._rlock:
KeyboardInterrupt
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/process.py”, line 93, in run
self._target(*self._args, **self._kwargs)
KeyboardInterrupt
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/utils/data/dataloader.py”, line 34, in _worker_loop
r = index_queue.get()
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/synchronize.py”, line 96, in enter
return self._semlock.enter()
KeyboardInterrupt
KeyboardInterrupt
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/queues.py”, line 341, in get
with self._rlock:
File “/home/apil/anaconda3/envs/fastai/lib/python3.6/multiprocessing/synchronize.py”, line 96, in enter
return self._semlock.enter()
KeyboardInterrupt
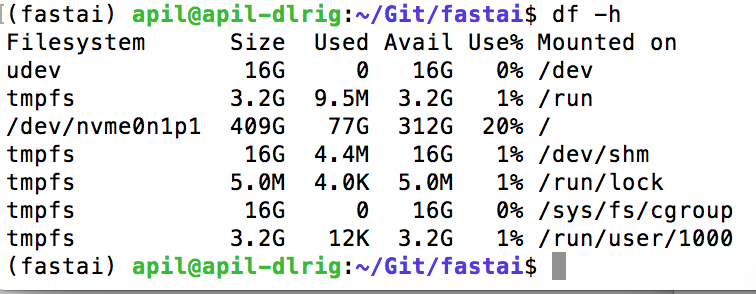
** Finally here’s my device shared memory numbers.** These are system defaults.
 ).
).