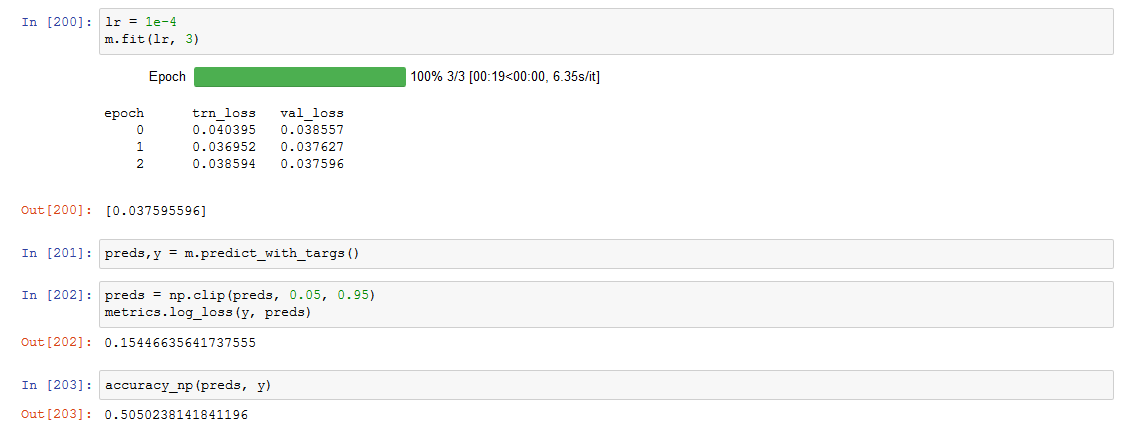
I’m doing the NCAA ML competitions on Kaggle as a way to practice on a structured dataset. I’ve built a relatively simple model using a few key statistics and just two categorical variables.The model works and I’m showing good results when running m.fit. However, I’m getting a high loss score and poor accuracy when running predict(). Can anyone help me understand what’s going on here? Why might there be such a discrepancy between the two loss scores? I thought they would be similar since they are both being run on the validation set.
2 Likes
could it be that you’ve fit your model to the validation set?
if you change your parameter too much based on your validation loss you might see a difference between that and the test loss.