Coudl you pop your whole notebook into a gist?
You need to multiply it by 255 before you change it to uint8 - since otherwise making it uint8 will truncate them all to zero!
Before you plot the data in the loop, print it. You need to have values in the range zero to 255, of data type uint8. If you don’t, take go through the steps manually and find where you need to make a change to get this range.
I see that earlier on you print out newdata[], and it’s around 1e-5; that would suggest you need to multiply by 100,000 or so in order to get something you can plot.
I was able to make it work…
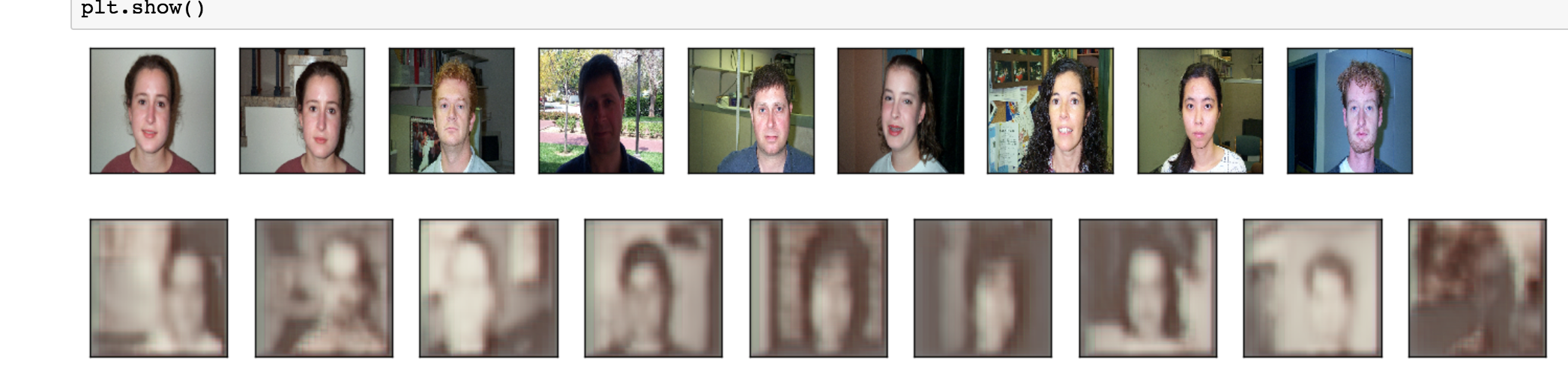
The images print now…
I thought it fit it well.
419/419 [==============================] - 6s - loss: 0.0423 - val_loss: 0.0413
Epoch 45/50
419/419 [==============================] - 5s - loss: 0.0409 - val_loss: 0.0400
Epoch 46/50
419/419 [==============================] - 6s - loss: 0.0396 - val_loss: 0.0387
Epoch 47/50
419/419 [==============================] - 5s - loss: 0.0384 - val_loss: 0.0375
Epoch 48/50
419/419 [==============================] - 6s - loss: 0.0372 - val_loss: 0.0365
Epoch 49/50
419/419 [==============================] - 5s - loss: 0.0361 - val_loss: 0.0354
Epoch 50/50
419/419 [==============================] - 5s - loss: 0.0351 - val_loss: 0.0344
But I am not sure how to read the results.
I can see some similarities but it might be that i just want to see my model work 
I only had 420 images to train so I think this might actually be working pretty well.
1 Like
That looks great! Would be good if you can re-create the original colors too…

Cool project @garima.agarwal ! I wonder how your reconstructions might change without max pooling. Maybe that spatial downsampling contributes to some of the smoothness/bluriness you see? Without max pooling and upsampling it will take longer to train but maybe it would help. You could consider strided convolution like they use in Alec Radford’s DCGAN paper (https://arxiv.org/abs/1511.06434). In keras you could use strided conv2d for the encoder and the Deconvolution2D layer for the decoder.
hey… honestly my hope from this project was to be able to cluster the training set and then identify the test images as one of those cluster… I am not sure if I can achieve that right now… I think if I could identify the cluster the accuracy i am at right now might have been ok to achieve that result…
Looking good!
If your goal is to figure out whether two images are of the same person, you may want to look at: https://www.quora.com/What-are-Siamese-neural-networks-what-applications-are-they-good-for-and-why .
Keras implementation here: https://github.com/fchollet/keras/issues/242#issuecomment-114996378
2 Likes
Love this thread! Idea of using kmeans to auto create classes seems great! How are you generating validation set?Split it from training set?