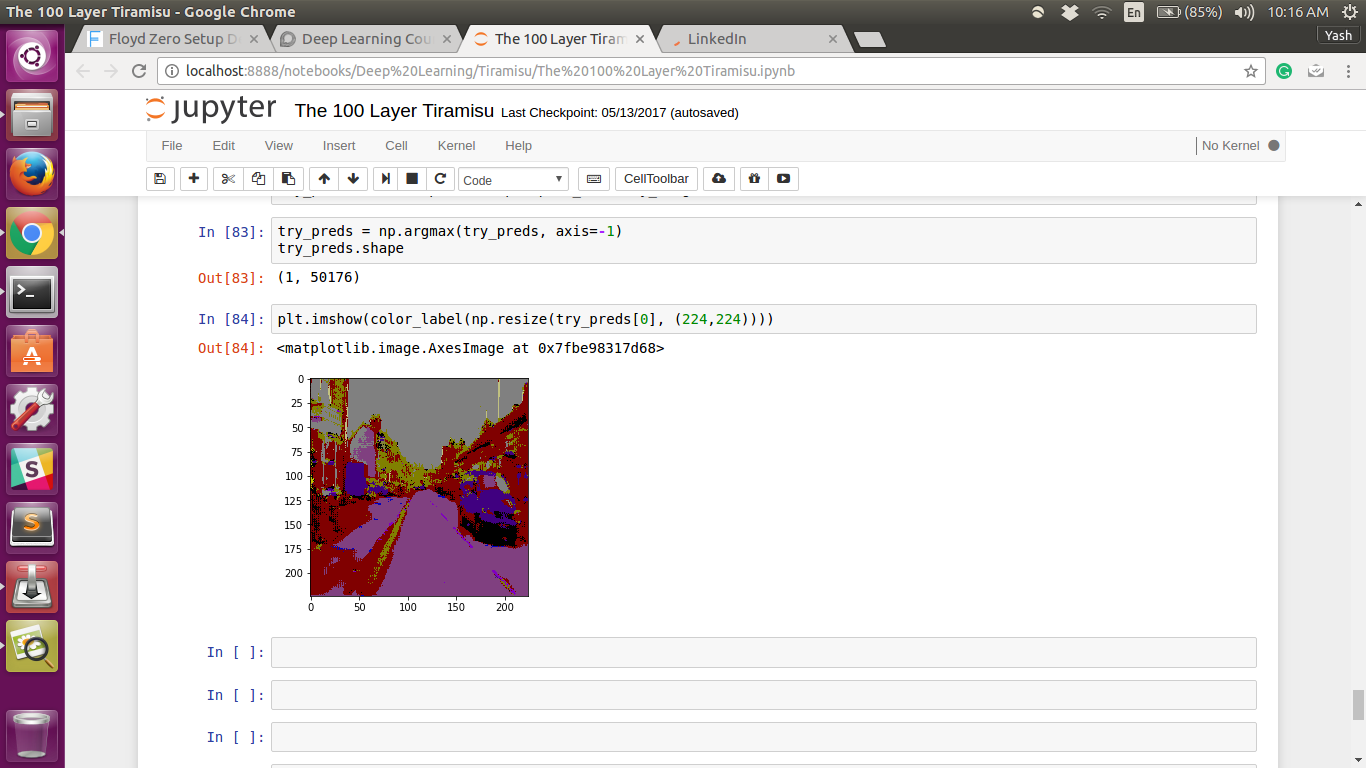
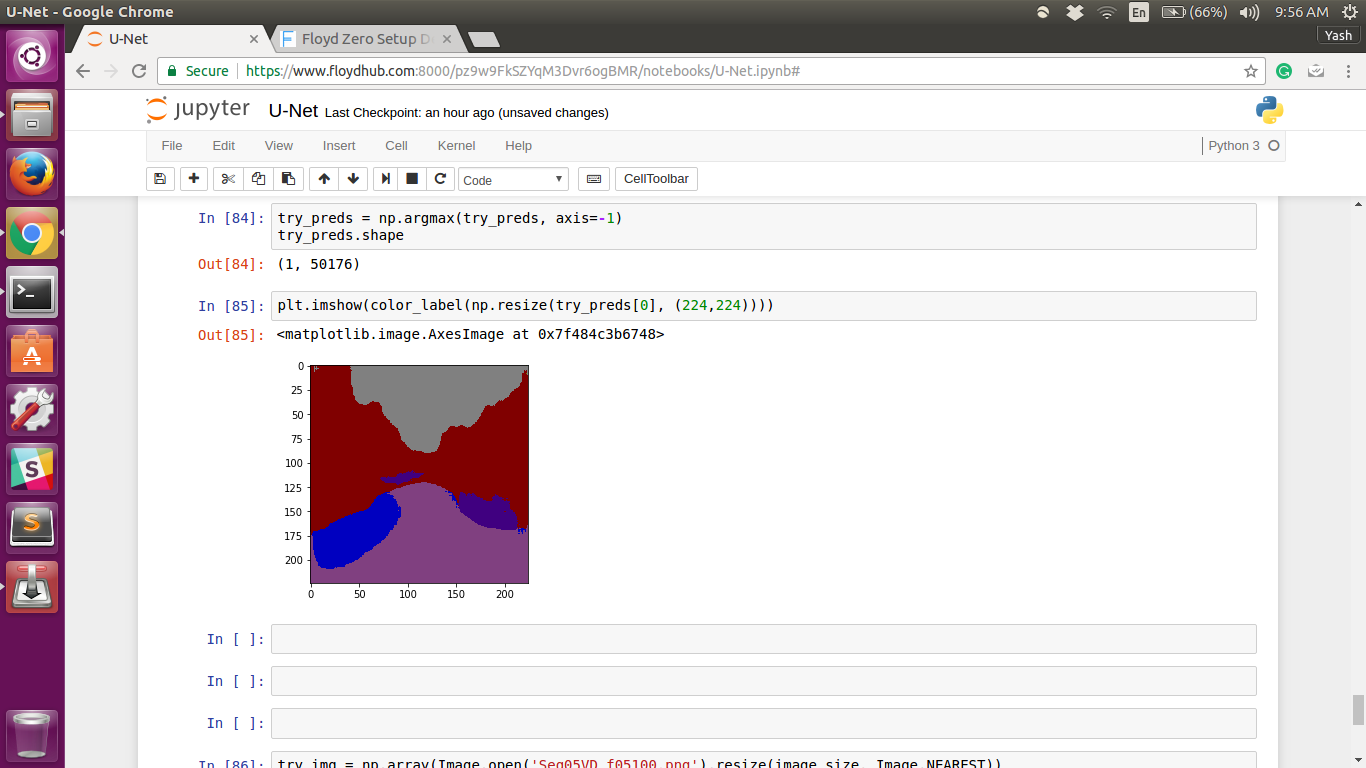
@jeremy I thought of using U-net on the camvid dataset, but the predictions I got weren’t very good. I trained the Tiramisu for only 2 iterations getting an accuracy of 56%. After this, I trained U-net for 30 iterations and got an accuracy of 66%.
These are the predictions I got for the same image for Tiramisu and U-net.
Are you using the large tiramisu from lesson 14 ?
If so, how much memory is the model using?
I have a gtx 1070 and the large model from lesson 14 gives me an out of memory error.
I am sorry for hijacking this thread, but I am really stuck
@jeremy Does U-net perform better when it has to segment small details like in satellite image feature detection competition on kaggle or on medical data? Is this the reason why U-net isn’t performing on the camvid dataset?
U-net and tiramisu should both be particularly good at that - see how they perform well on trees, for instance.
I don’t see why U-net wouldn’t go well on Camvid - although it might just be that there’s not enough data for it train well. Densenet (tiramisu) is good at handling small datasets.
@yashkatariya - Try varying the block depth (number of layers), as well as the network depth (number of unet blocks) to see if that has any effect.
An experiment I’ve been wanting to get around to was using densenet style linear filter growth on unet instead of 2^x to see what effect it has generally. With all the new papers coming out on how our networks’ parameter space are potentially doing memorization, I find myself drawn to simpler and smaller networks like ENet again.
@jeremy The picture had a tree, but it wasn’t able to segment it.
I guess by increasing the network depth and number of layers per block as @haresenpai said, the predictions will improve. But we would need to add many layers for this to work.