I’m wondering if there’s an issue in the notebook lesson2-download.ipynb, associated with part 1 of the course Practical Deep Learning for Coders, v3. Specifically, associated with the video at https://course.fast.ai/videos/?lesson=2. In one of the markdown cells in the section ‘Learning rate (LR) too low’, I am seeing the following:
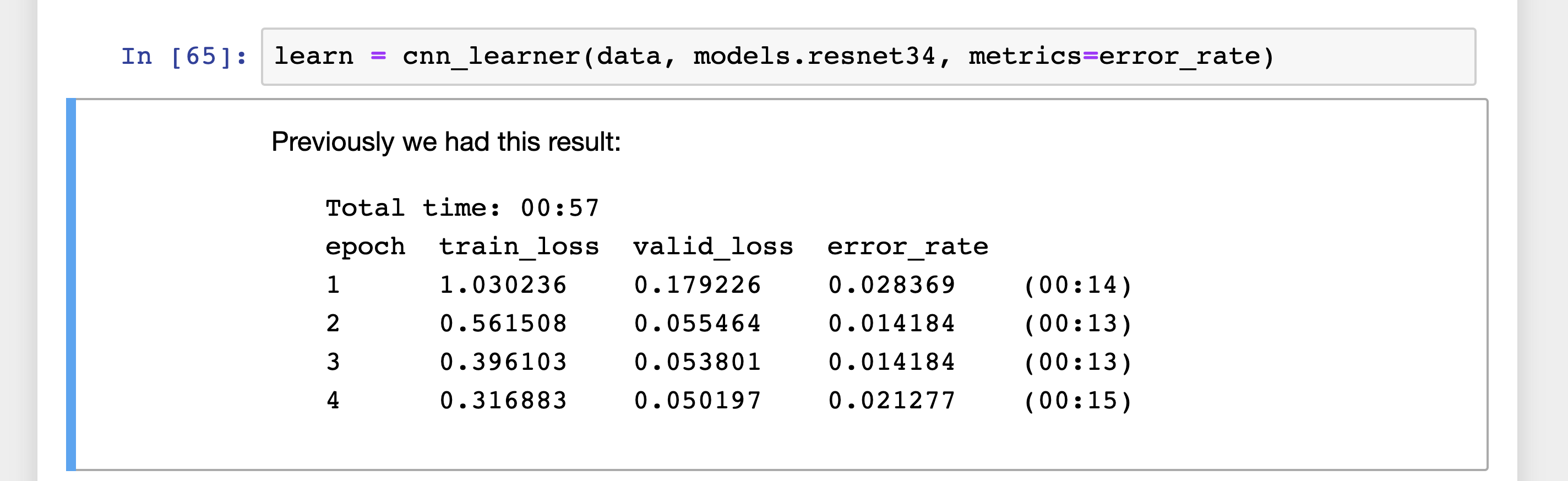
The text in the cell, starting with ‘Previously we had this result’ (suggesting these were results from a training run with an appropriate learning rate), was there when I first opened the notebook. I didn’t write it, and I didn’t edit it at all. Yet we see a train_loss that is substantially larger than valid_loss in all cases.
But why should train_loss be (an order of magnitude) larger than valid_loss? In the video, this isn’t questioned by the audience.