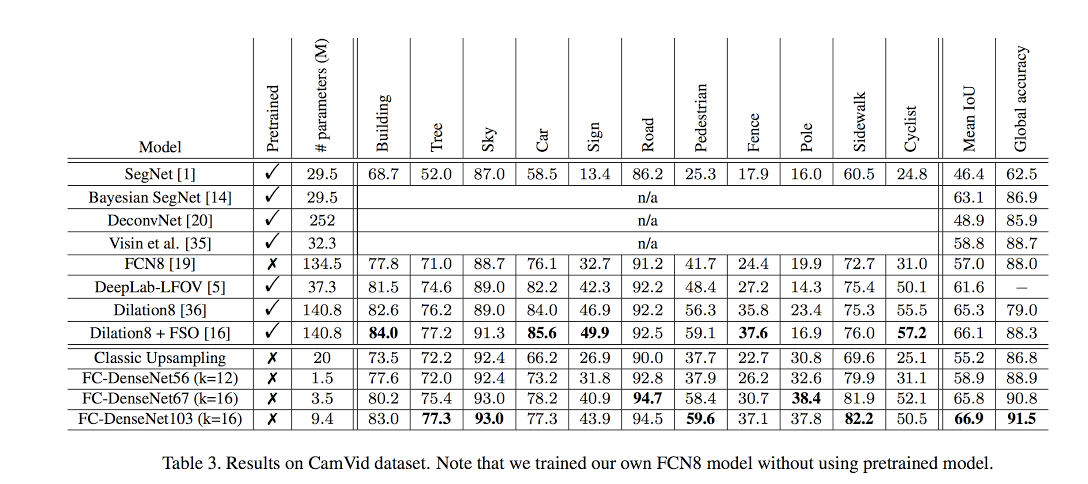
Me and @shgidi are trying to apply the Tiramisu for background removal. After training it with CamVid and with 20K images of people only images from COCO, we realized the Tiramisu accuracy for people (i.e: = pedestrian + cyclists…) is not too good (see original Tiramisu paper)
We’re also trying to apply FCN, but it’s not looking too promising either.
Any suggestions for architectures and training methods that might suit background removal?
Comparing to this Deep Matting paper I am not sure why the Tiramisu is not performing as well as that, since it looks much more advanced in terms of architecture and bigger.
Has anyone taken a shot in trying to implement Mask-RCNN ?
There’s a Mask-RCNN implementation on github somewhere, I don’t think anyone’s released their weights for it yet. Still waiting on FAIR to release Mask-RCNN official code
@amiltonwong - I will try to share the output. As noted, our training did go well reaching 0.91 accuracy, it’s just that if you want to do more fine edge detection, it’s not enough. If you predict only the background class for the COCO dataset, you’ll reach automatically ~0.81 accuracy.
Interestingly we tried to apply an FCN on top of the Tiramisu which seemed to improve things.
I have a question, please excuse my ignorance.
Can you please explain the problem or give a link?
Is the pictures coming from same camera in same position?