I guess we won’t know until someone actually tries it 
Maybe nobody wants to loose the 300$ credit by signing-up and not using it  (if no available GPU) like I did last year and now I’m not eligible anymore with my own account.
(if no available GPU) like I did last year and now I’m not eligible anymore with my own account.
I’ve tried it now with a fake account and it seems to work with GPU though, but I’m still not sure because I did not succeed to start jupyter notebook (had some privilege-related errors).
But I think it should work because when listing available hardware of the instance inside the terminal, there is also a Tesla K80 entry (highlighted below with white).
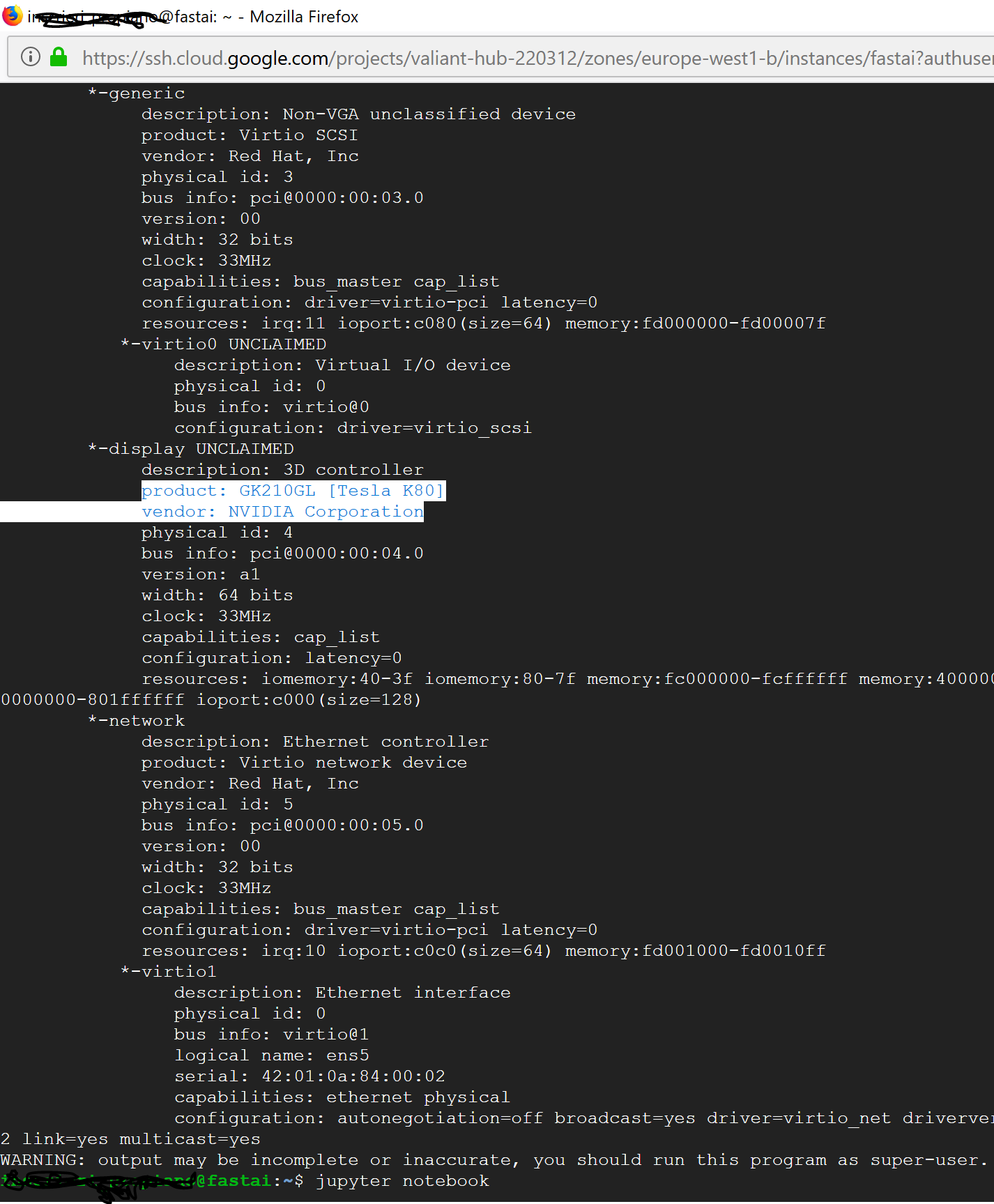
I will come back with an update if succeeding to start Jupyter notebook, but first I have to finish watching the first lesson. 
1 Like
BTW: The best datacentre to choose would be Europe-West1 (Belgium) since it is the nearest with GPU option.
All other European datacentre I’ve tried-out, seem to have no GPUs available (did not try all).
1 Like
Good man! I don’t mind making new accounts as long as i can link them to the same credit card
Is it possible with the same credit card on another GCP account?
I’ve used another credit card since on Azure (some time ago) it refused the same card for another account.
No idea . Probably not
GCP works like a charm for me, managed to run the notebooks! thanks for the europe-west1 region tip, Teo. Also only 2 out of the 3 zones in the region have GPUs (europe-west1-b & europe-west1-c).
Here are the details: https://cloud.google.com/compute/docs/regions-zones/
I also signed up last year, used about $5 of credit and a week ago was announced the credit expired ![]()
I’ll try to use Colaboratory, but I first have to go through the course!
Finally, I’ve made the Jupyter notebook also running (problem: prior I’ve used an old cli script from v2 course).
If it helps anyone, below you’ll find the cli script for creating an instance, on European soil, which fits exactly the standard compute instance, which is recommended in the course’s Google Cloud set-up guide.
export IMAGE_FAMILY="pytorch-1-0-cu92-experimental"
export ZONE="europe-west4-b"
export INSTANCE_NAME="fastai-standard-compute"
export INSTANCE_TYPE="n1-highmem-8"
gcloud compute instances create $INSTANCE_NAME \
--zone=$ZONE \
--image-family=$IMAGE_FAMILY \
--image-project=deeplearning-platform-release \
--maintenance-policy=TERMINATE \
--accelerator='type=nvidia-tesla-p4,count=1' \
--machine-type=$INSTANCE_TYPE \
--boot-disk-size=200GB \
--metadata='install-nvidia-driver=True' \
--preemptible
This seems one of only two possible standard compute options in Europe, since Tesla P4 (the course recommendation, which is way faster than K80, but far less expensive than P100/V100) is only available for europe-west4-b and europe-west4-c zones, as you can see below:
GPU machine types | Compute Engine Documentation | Google Cloud
Maybe I’m missing something, but for some reason, the GPU reference above seems to be in contradiction with the documentation link shared by Virgil:
1 Like
Hey guys, I went through the lesson using Google Colab (using the notebook posted by Virgil) and everything works fine, but the training seems a bit slow. Is Google Cloud faster? Is it worth doing all the GCP setup (Colab worked with no setup at all) ? What are its advantages?
Totally worth setting up GCP!
Advantages :
- training can run 10x faster (on P100 VM at least)
- after initial setup everything will work out of the box (In colab you’ll have to run the whole packages setup every time).
Also those 300$ in credits should go a long way (more than enough to finish this course. maybe enough to do the advanced one too).
I expect problems in future lessons on colab, but I do intend to try and run at least the basic notebooks in colab too.
2 Likes
BTW, there’s an official Colab notebook for lesson 1 too (see https://forums.fast.ai/t/lesson-1-official-resources-and-updates/27936 with Lesson 1 notebook for google colab ).
It does seem slow and for resnet34 I had to set bs=12 instead of bs=16 like they did, because I got a ‘bus error’ (ie. not enough GPU memory). For resnet50 they set bs=10 which works.
It feels to me that using resnet is a cheap trick. Your training is not any smarter/faster, you are just building upon a huge pre-trained NN which is awe-inspiring but you have no way to control.
1 Like
The point of using a big pretrained net is you get really fast to a very good baseline. That is the state of the art recommended approach for most vision problems today. From there it’s your choice if you dig deeper to understand what’s going on to make your models better. OTOH you can use this powerful model you’ve already trained for your problem to train smaller models much better (this knowledge distillation technique should be covered in future lessons, but you can start looking into it from this paper https://arxiv.org/abs/1503.02531 ).
If you look at the actual implementation of the training procedure, you’ll see there’s quite a bit of “smart” in the backend (e.g. : https://arxiv.org/abs/1803.09820 ).
You can get a better feel of how good the framework is if you try to match the accuracy obtained in fastai in another framework. Then compare how much time it took you to write the code to do all you need and how much time the training takes on similar HW.
I played around with a kaggle competition last night and using code based on the Lesson1 notebook I got to around 96% accuracy in 30-40 min ( dowloading dataset + coding + training). Will share once I clean it up. I have much more experience with keras & tf but it would’ve taken me at least as much time just to write the data preparation code. Maybe I will try to match the result in keras during the weekend just for comparison.
I have little experience in this area, but I dislike the fact that there is a fastapi python library too.
It’s easy to code a ‘happy path’ into your API and then the examples look really short and powerful. Of course, once you need to change anything you have to dig down and then you see if the API is really well thought of or just veneer.
Knowledge distillation sounds cool to me as it also hides the implementation detail. It’s a form of obfuscation. I remember reading that some Google guys showed you could make an equivalent single-layer NN for a multi-layer NN.
I found very interesting the article you suggested ( https://arxiv.org/abs/1503.02531 ). I was guessing if you already tested to shrink a model training on a small deploy device. It happen to me often to load deep learning solutions on very small devices with only 4 or 8 cores and limited amount of memory and bandwidth. But I never attempted this approach…
1 Like
I just tried running ConvLearner on the “3”/“7” images dataset and Google Colab was about 7 times faster than my CPU  (I actually have Linux in VirtualBox and I only gave it 4 of the 8 i7 cores I have, but still).
(I actually have Linux in VirtualBox and I only gave it 4 of the 8 i7 cores I have, but still).
So while Colab might be slow, it sure beats the CPU.
1 Like
It can work but it depends on how complex your problem is vs how big the network. No rule of thumb for it, you just have to try it 
Feel free to check out the other articles on distill.pub. They are all of great quality.
Regular expressions get complicated really fast. Note that ImageDataBunch.from_name_func allows you to set a label_func= argument which is a function you can define to label each image. I find it easier for me as instead of grouping with regexp I can just do str.rfind(".") and then extract substrings manually in Python.
For those who had errors on Friday during Google Cloud setup (either because of gcloud-cli, or other packages), below there is an alternative how to do the entire setup, from creating an instance to accessing/running jupyter notebook in the browser:
As far as I remember Fedora distros were plagued with errors and even one Ubuntu had trouble.
1 Like