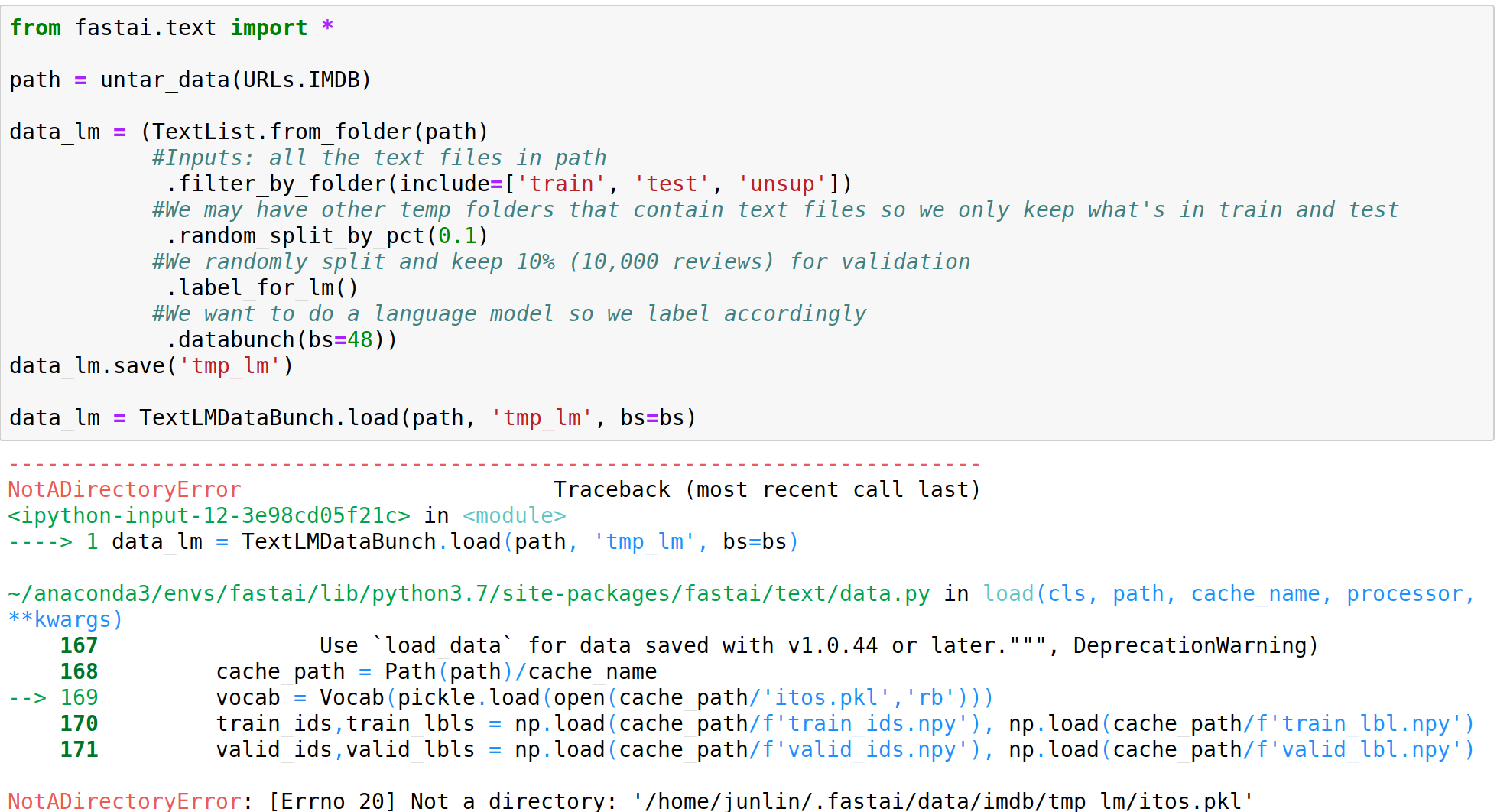
NotADirectoryError: [Errno 20] Not a directory: '/home/junlin/.fastai/data/imdb/tmp_lm/itos.pkl'.
Minimal example that reproduces this:
from fastai.text import *
path = untar_data(URLs.IMDB)
data_lm = (TextList.from_folder(path)
#Inputs: all the text files in path
.filter_by_folder(include=['train', 'test', 'unsup'])
#We may have other temp folders that contain text files so we only keep what's in train and test
.random_split_by_pct(0.1)
#We randomly split and keep 10% (10,000 reviews) for validation
.label_for_lm()
#We want to do a language model so we label accordingly
.databunch(bs=48))
data_lm.save('tmp_lm')
data_lm = TextLMDataBunch.load(path, 'tmp_lm', bs=48)
I ran into this, too. The solution is buried in the Traceback (see line 167 above). For some reason, the DeprecationWarning isn’t being thrown at the top of the Traceback, where it should be (and would be more visible).
Try this:
from fastai import *
data_lm = load_data(path, bs=bs)
@jeremy Is load_data intended to be a @classmethod of DataBunch? It seems to work just fine as a standalone, but might be more clear as a @classmethod of DataBunch. I’d be happy to submit an Issue and/or PR on GitHub, if needed…just thought I’d ask here first.
The example you linked to suggests that load_data is intended to be a standalone function of the basic_data module rather than a @classmethod of DataBunch.
It is true that the URL is missing the file extension (.tgz), but that is not a bug (they probably add it at a later point). In fact, I have worked with someone else’s trained model and to pass it to Fastai I uploaded the files to Amazon S3 just like the IMDB file you mention, and in the URL I had to omit the .tgz extension so it would work!