Below is my personal opinions, I would like to make a pr, but before that, what is your opinions ?
-
show_batchdidn’t tell me what my model will see in a batch.
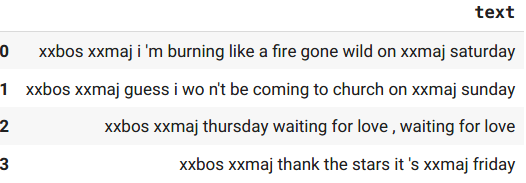
Actually there is variable number of pads behind sentences.
- I can’t teach other very newbies what is actually passed to your model with this beautiful visual.
- I can’t 100% use
show_batchto confirm my data loading is correct.
-
If not showing the pad is to prevent too many words showed, we may be able to just use
trunc_at, which limited number of words showed per cell. -
If your
PADis notxxpad, it still appears.

And it seems that we can’t changePAD(?), so this may be meaningless.(?)
PS. Here is where this happened.
class Numericalize(Transform):
...
def decodes(self, o): return L(self.vocab[o_] for o_ in o if self.vocab[o_] != PAD)
!!! ↑↑ here ↑↑ !!!