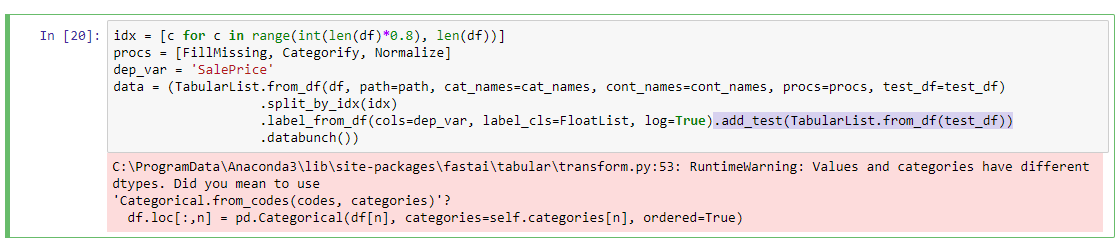
Using the Titanic Kaggle datasets (train.csv and test.csv), I am trying to do very simple tabular data NN work.
I am following the example from the fast.ai docs pretty much exactly, but when creating the TabularDataBunch I am using this line:
data = TabularDataBunch.from_df(path, df_out, dep_var, test_ds=test_df, valid_idx=range(100), procs=procs, cat_names=cat_vars)
However, I note that data.test_ds is None. This makes sense, because in the class definition of TabularDataBunch, we have
@classmethod
def from_df(cls, path, df:DataFrame, dep_var:str, valid_idx:Collection[int], procs:OptTabTfms=None,
cat_names:OptStrList=None, cont_names:OptStrList=None, classes:Collection=None, **kwargs)->DataBunch:
"Create a `DataBunch` from train/valid/test dataframes."
cat_names = ifnone(cat_names, [])
cont_names = ifnone(cont_names, list(set(df)-set(cat_names)-{dep_var}))
procs = listify(procs)
return (TabularList.from_df(df, path=path, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_idx(valid_idx)
.label_from_df(cols=dep_var, classes=None)
.databunch())
And, well, test_ds doesn’t show up in any of the arguments, and so it would get passed in kwags, but I note that in the body, kwargs doesn’t get used anywhere.
The result of this is that, further down the road, I can’t do
learn.get_preds(DatasetTypes.Test) because I’ll get an error about NoneType not supporting the action.




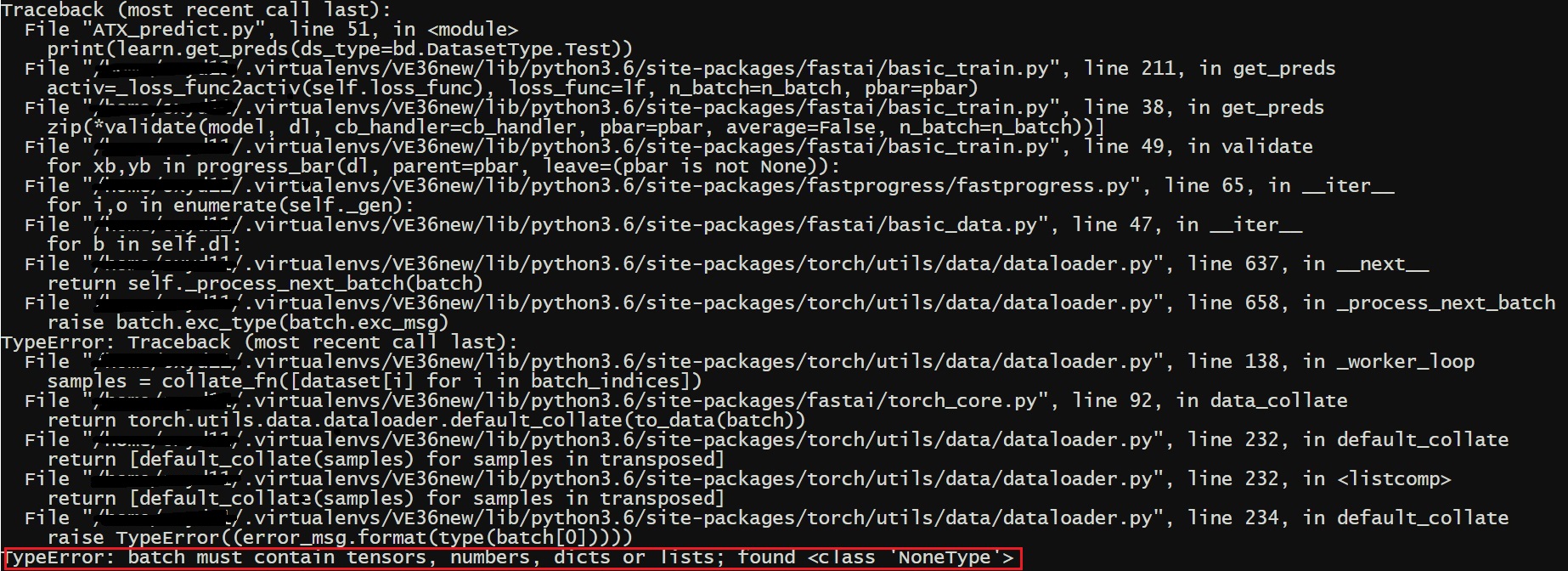
 Same error.
Same error.