I am getting a different result when trying to replicate the output of learner.fit_one_cycle() after the training process is complete.
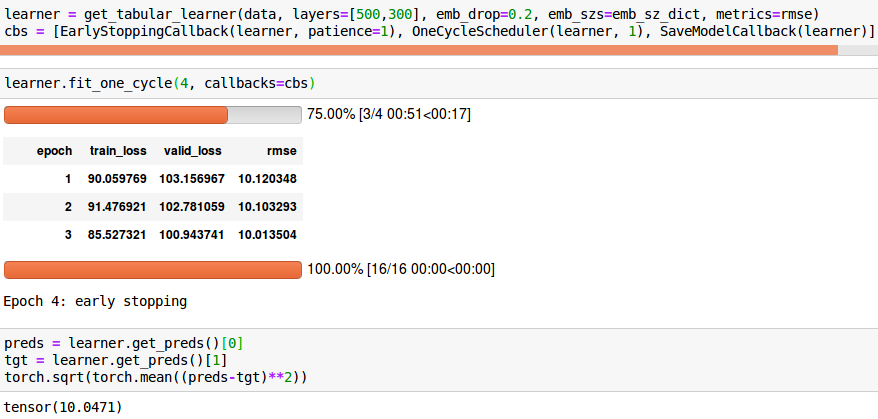
Anyone know why the rmse from .fit_one_cycle() does not match the result from calling .get_preds()?
I am getting a different result when trying to replicate the output of learner.fit_one_cycle() after the training process is complete.
Anyone know why the rmse from .fit_one_cycle() does not match the result from calling .get_preds()?
Because what you see during training is the mean of the rmses per batch. What you compute at the end is the real rmse, and they are close to each other, but not the same thing.
Thank you for the quick response, much appreciated. To ensure I understand correctly, this means it is beginning to overfit during the final epoch? I tried this many times (dozens), and every single time the val_rmse was lower after training, while in theory this should happen 50% of the time.
*higher after training
No, it means what the training loop sows you isn’t the real exp_rmse. And It will always be slightly lower. To correct this, you have to implement exp_rmse like Fbeta is in metrics, so that it returns the right value.
What the trainnig loop shows is:
average over batches of torch.sqrt(torch.mean((pred_batch-tgt_batch)**2))
When the true rmse is, as you pointed out:
torch.sqrt(torch.mean((pred-tgt)**2))
The two aren’t equal, and the latter is always going to be greater than the former.
Ok yeah that explains it, thanks!