That’s strange. The NaN values should indeed be replaced by the median, or #nan for categorical columns.
The MarkDown1_na etc columns indicate that some transform has been applied, but I don’t know why it shows this behavior. Maybe someone else can help!
FillMissing works on continuous data, as the documentation states. Categorical variables can absolutely have missing values. They get a special spot in the embedding matrix
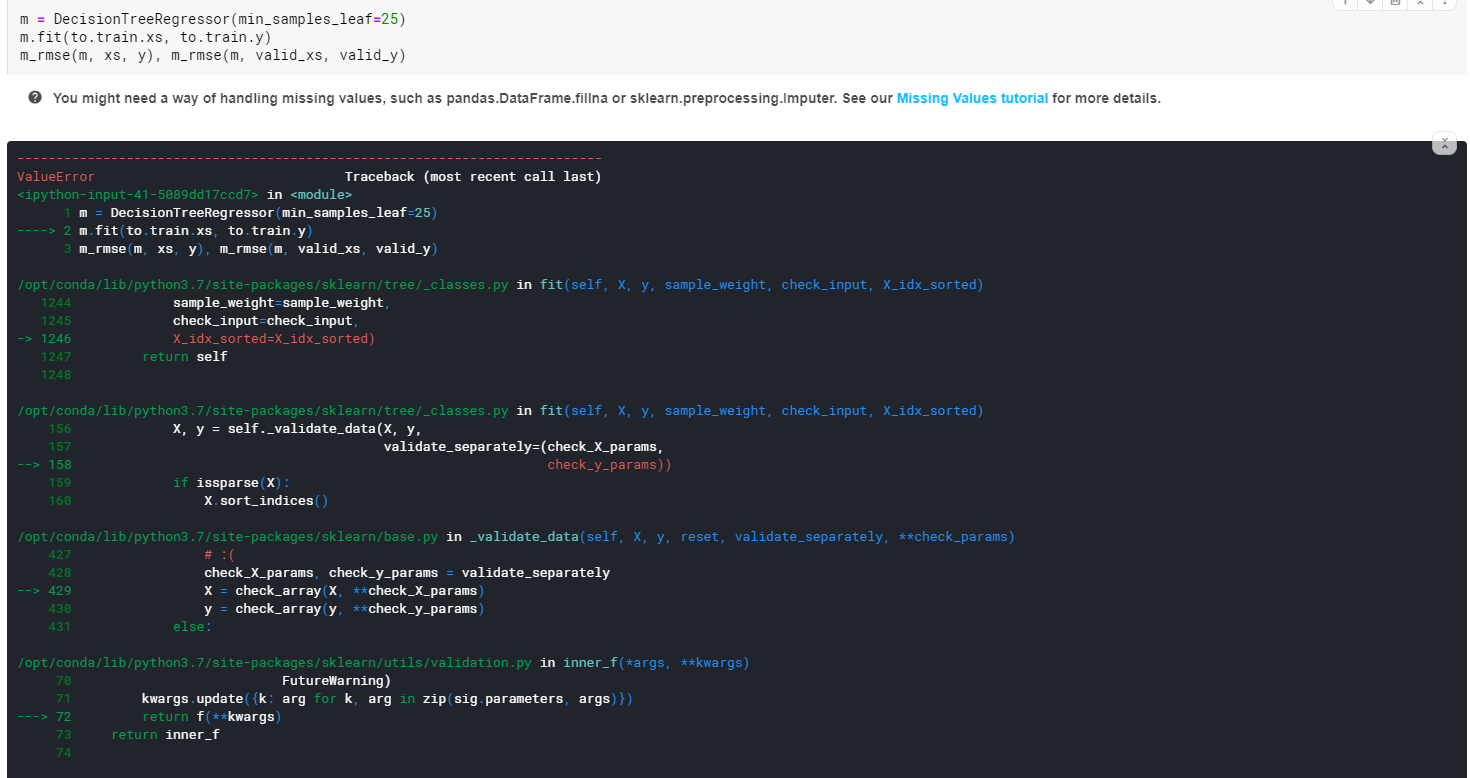
ok got it but when I run the decisiontreeregressor it throws an error because of missing values (screenshot), so how do I handle this using tabular pandas?
You should investigate your cat and cont variable names to make sure that they are how you would expect them to be. Perhaps something that should be categorical is being thrown into the continuous
(Note that this is a helper function, but that doesn’t mean it works on every single scenario)
The only columns with missing values are Markdown1-5 and when I list the cont and cat variables, I see Markdown1-5 columns appear in cont variable so it is continuous. But yet Tabularpandas is unable to replace these missing values. Not sure what I am missing here. If its not too much trouble, you can check the notebook - https://www.kaggle.com/ritepaul/rp-walmart-sales-forcast