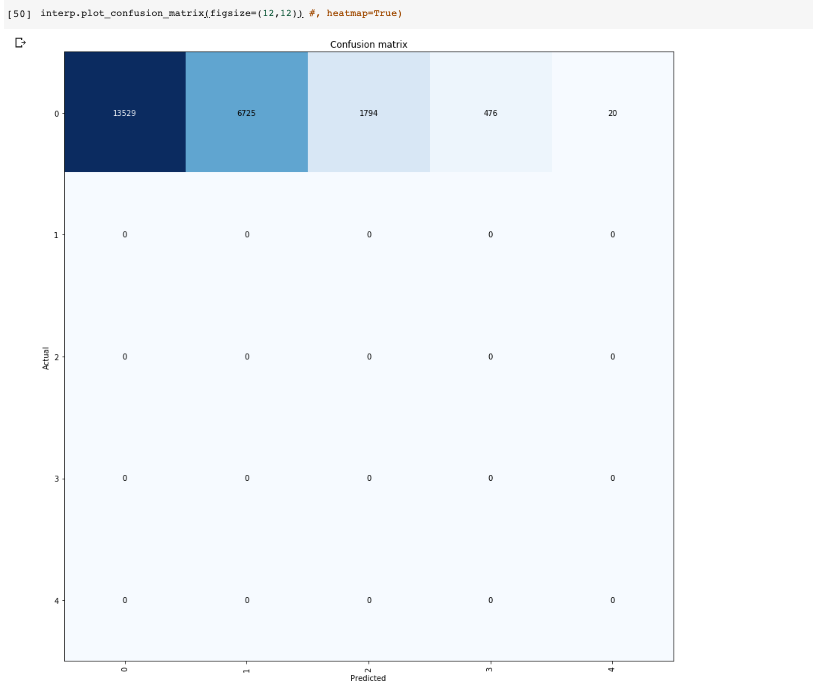
I’ve created a new tabular learner and I’m having hard time interpreting the results. I’m trying to create a classifier with five potential classes. During training I’m getting accuracies of over 99%, with some variable validation loss ~(.5 - 1.5). I think I have a reasonably sized data set, after splitting and adding the a test set its made up of the following:
TabularDataBunch;
Train: LabelList (100779 items)
Valid: LabelList (25194 items)
x: TabularList
Test: LabelList (22544 items)
x: TabularList
After trying to get predictions, my learner is consistently returning accuracies of ~74%:
Accuracy tensor(0.7472)
Error Rate tensor(0.2528)
What do you think could be causing such a big difference with my training/test set? I’ve trained the model multiple times using the split_by_random without passing a seed (to get a different training/validation set) but I’m receiving similar results.
The following is a code snippet:
`dep_var = ‘label’
cat_names = [‘three’,‘variables’,‘here’]
cont_names = [‘41’,‘variables’, ‘here’]
procs = [FillMissing, Categorify]
data = (TabularList.from_df(df,cat_names=cat_names,cont_names=cont_names, procs=procs)
.split_by_rand_pct(0.2)
.label_from_df(cols=dep_var)
.add_test(test_dframe, label=‘label’)
.databunch(bs=100)
)
learn = tabular_learner(data, layers=[200,100], metrics=[accuracy, error_rate], emb_drop=0.1, callback_fns=[ShowGraph]))`
When I run the following, my accuracy is show much higher on than on the test set:
probs, val_labels = learn.get_preds(ds_type=DatasetType.Valid)
print(‘Accuracy’,accuracy(probs,val_labels)),
print(‘Error Rate’, error_rate(probs, val_labels))
Accuracy tensor(0.9977)
Error Rate tensor(0.0023)
Any clarification or ideas would be really helpful, thank you!