Updated – It’s solved 
I have a question regarding logic behind gradient boosting trees.
I hope it’s a relevant thread for this question. I was stuck somewhere and couldn’t find a better place to ask. If someone knows about gradient boosting, please help.
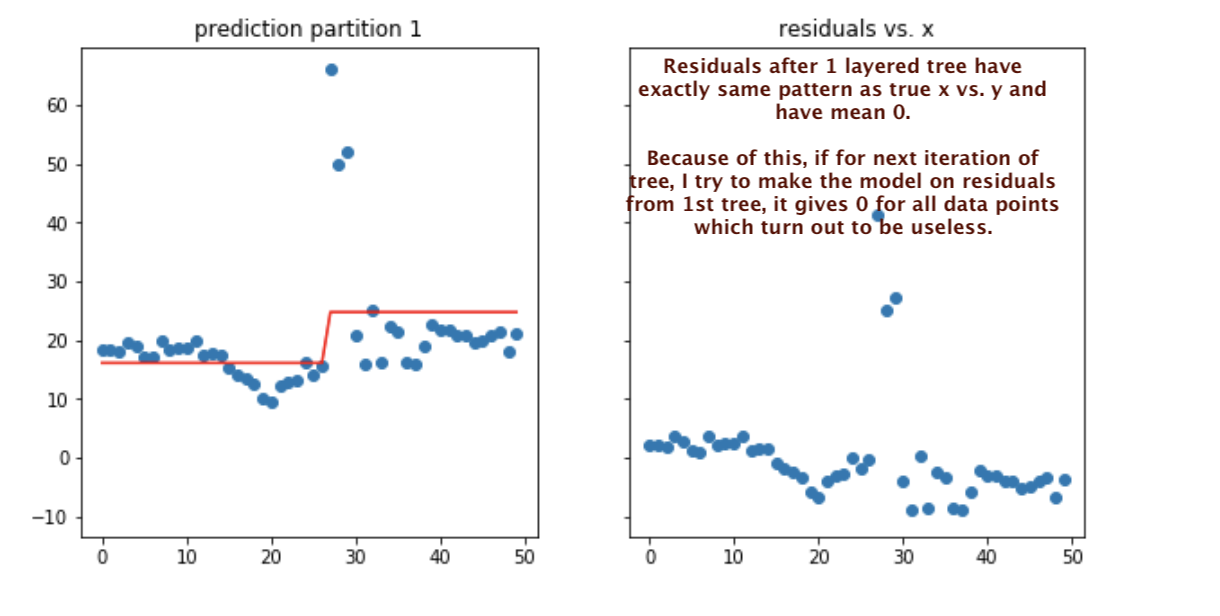
As per my understanding (which is at amateur stage so-far), gradient boosting makes the 1st tree similar to random forest. After that, other trees are made sequentially (not independently like RF) and are modeled on the residuals of previous trees. The idea is simply to take weak modeled tree and improve it step by step by modeling the residuals until our final residuals become patternless (random with mean = 0).
I was trying to implement this idea on simulated data, but algo is failing to improve model after the first tree. Residuals coming from 1st prediction have exactly same pattern as target variable. And if I model again taking calculated residuals as target, the model predicts only 0 as mean for both partitions are 0. But if this keeps on happening, my model would never improve.
Here is the snapshot of
1. scatter plot of prediction from 1st tree ,
2.residuals of predictions from first tree
Here is the code of GB I used (from scratch)
https://github.com/groverpr/Intro-to-Machine-Learning/blob/master/algo_scratch/gradient%20boosting%20from%20scratch.ipynb