You can get the embedding vectors through model.embs.parameters()
try something like
embedsnp = list()
for param in model.embs.parameters():
embedsnp.append(param.data.cpu().numpy())
(Indent that last line)
You can get the embedding vectors through model.embs.parameters()
try something like
embedsnp = list()
for param in model.embs.parameters():
embedsnp.append(param.data.cpu().numpy())
(Indent that last line)
I’m trying to understand the MixedInputModel.forward method inputs (x_cat and x_cont). Where is it specified there will be two inputs? I’m interested in extending forward to include a third class of input type that is a sequence of integers to which I’ll apply an additional pre-computed embedding on each element, flatten and then torch.cat with the continuous and categorical Tensors. I thought maybe the parameters expected by forward were controlled by the getitem method in ColumnarDataset. Any thoughts? Thanks for any insight.
For the MixedInputModel, what is the difference between emb_drops and drops? They are both passed to the Dropout function:
self.emb_drop = nn.Dropout(emb_drop)
self.drops = nn.ModuleList([nn.Dropout(drop) for drop in drops])
Do these parameters essentially do the same thing? Would a model use only one of these, or is there a use case for having both types of dropout?
Emb drop applies dropout on embedding weights and drops essentially do the same but for linear layers. So you can define different level of dropout for both independently.
hey i am working on this structured data model for a completed competition on kaggle (airbnb). I am having trouble getting the get_learner to work . If anybody could look at the code and give me suggestions on how to move forward it would be great
Hello @shriram ,
I have a similar problem like you but my setup crashes one step later when I want to call lr_find().
I use the proc_df() supplied with fast.ai to process my dataframe into a format that should be able to be handled later. For that I use do_scale=True to scale my continuous data and ignore_flds= to ignore the categorical data. I use the the mapper and the na_dict/nas from the train df on the test and val df (which I separated before).
After that I create a MixedInputModel(...) and with that a basic model with bm = BasicModel(model, 'binary_classifier') (this approach is from https://github.com/KeremTurgutlu/deeplearning/blob/master/avazu/FAST.AI%20Classification%20-%20Kaggle%20Avazu%20CTR.ipynb by @kcturgutlu).
Next, I created the model data with md = ColumnarModelData.from_data_frames(...).
After that I can create the learner with learn = md.get_learner(...).
But then it crashes when I call learn.lr_find() with the following output:
...
~/fastai/courses/dl1/fastai/column_data.py in <listcomp>(.0)
113 def forward(self, x_cat, x_cont):
114 if self.n_emb != 0:
--> 115 x = [e(x_cat[:,i]) for i,e in enumerate(self.embs)]
116 x = torch.cat(x, 1)
117 x = self.emb_drop(x)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
489 result = self._slow_forward(*input, **kwargs)
490 else:
--> 491 result = self.forward(*input, **kwargs)
492 for hook in self._forward_hooks.values():
493 hook_result = hook(self, input, result)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/sparse.py in forward(self, input)
106 return F.embedding(
107 input, self.weight, self.padding_idx, self.max_norm,
--> 108 self.norm_type, self.scale_grad_by_freq, self.sparse)
109
110 def extra_repr(self):
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/functional.py in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)
1062 [ 0.6262, 0.2438, 0.7471]]])
1063 """
-> 1064 input = input.contiguous()
1065 if padding_idx is not None:
1066 if padding_idx > 0:
RuntimeError: cuda runtime error (59) : device-side assert triggered at /opt/conda/conda-bld/pytorch_1525909934016/work/aten/src/THC/THCTensorCopy.cu:204
Maybe this helps you?
Maybe somebody has another hint on what is not working?
I also tried debugging with ipdb (from IPython.core.debugger import set_trace; set_trace(), see https://pythonconquerstheuniverse.wordpress.com/2009/09/10/debugging-in-python/) but so far I could not pinpoint the problem.
Best regards
Michael
EDIT:
I found a better way to start the debugging when the error occurred with this helpful code (from https://stackoverflow.com/questions/242485/starting-python-debugger-automatically-on-error):
import pdb, traceback, sys
if __name__ == '__main__':
try:
learn.lr_find() # <-- put the function that crashes here!
except:
extype, value, tb = sys.exc_info()
traceback.print_exc()
pdb.post_mortem(tb)
The problem in my case comes from the torch embedding function.
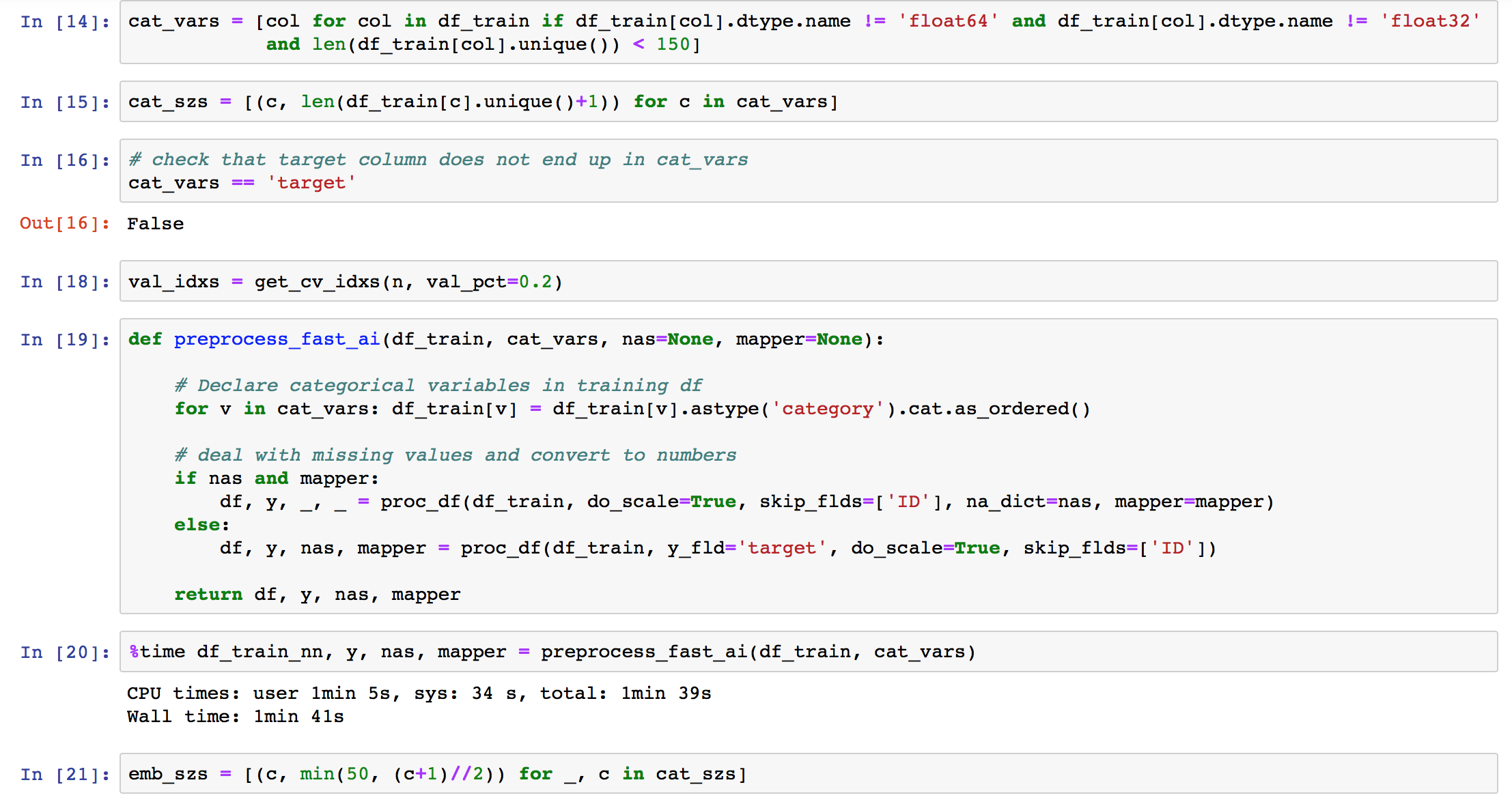
I created the embedding sizes with emb_szs = [(c, min(50, (c+1)//2)) for _,c in cat_sz] from the video. But the embedding sizes shouldn’t be a problem, right?
You’re getting a keyword error when ColumnarModelData tries to access columns from your categorical variables list. Earlier you converted those columns to one hot variables with get_dummies, so the categorical columns no longer exist. Instead of using one hot encoding and the sklearn encoder to manage your dataframe, use proc_df from the fastai library.
Thank you for the input. I removed the dummies and tried with proc_df and still seem to be getting the same error. Could you please elaborate what you meant so that I can have a better understanding. you can find the updated version of my code on the link below, in airbnbupdate.
Hi, Josh. I am having the same issue. I tried everything and nothing worked for me. Have you manage to solve it?
Today, I tried the rossman approach to another dataset and I’m still getting stuck at the same point (lr_find) with the same cryptic error message.
Therefore I looked closely at the data preparation. Maybe I’m missing a step which is not directly located in the data preprocessing part in the Rossmann notebook? My data preprocessing is also very similar to the one from Kaggle: Home Credit Competition (https://www.kaggle.com/davidsalazarv95/fast-ai-pytorch-starter-version-two/notebook), so I’m really wondering where the error could be located…
Here are my steps:
1.) set type of categorical variables:
for v in cat_vars: df_train[v] = df_train[v].astype('category').cat.as_ordered()
2.) run ‘proc_df’:
df, y, nas, mapper = proc_df(df_train, y_fld='target', do_scale=True, skip_flds=['ID'])
3.) generate log values of y for model data:
yl = np.log(y)
I was trying this out on my paperspace machine with a fresh conda update --all and gut pull.
I was also running the same notebook on my local machine without GPU and got a similar error:
~/anaconda3/lib/python3.6/site-packages/torch/nn/_functions/thnn/sparse.py in forward(cls, ctx, indices, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)
55
56 if indices.dim() == 1:
---> 57 output = torch.index_select(weight, 0, indices)
58 else:
59 output = torch.index_select(weight, 0, indices.view(-1))
RuntimeError: index out of range at /Users/soumith/code/builder/wheel/pytorch-src/torch/lib/TH/generic/THTensorMath.c:277
Interestingly, without GPU I can get additional information with the ‘args’ command in debug mode:
cls = <class 'torch.nn._functions.thnn.sparse.Embedding'>
ctx = <torch.autograd.function.EmbeddingBackward object at 0x1c291c5828>
indices =
1
(...in total 128x 1...)
1
[torch.LongTensor of size 128]
weight =
1.00000e-02 *
-8.4851
[torch.FloatTensor of size 1x1]
padding_idx = -1
max_norm = None
norm_type = 2
scale_grad_by_freq = False
sparse = False
Could it be the negative padding_idx? Unfortunately, it seems to get set outside of my code…
Am I missing a obvious step in the data preprocessing?
Hi!
If my memory serves me well, I did have that problem when trying to build my kernel. The problem was that the model expected something different than the Data Loader was giving it. In my case, it was that I hadn’t done the exact same pre-processing for my validation set as I was doing with my training set.
In step (1), have you tried calling apply_cats(df_valid, df_train) after the for loop?
I suggest you try to ‘debug’ your DataLoader and check whether is yielding the data that you expect it to.
thank you for your reply (and you excellent kaggle kernel)! 
I was trying your approach with separated train and val df and ‘ColumnarModelData.from_data_frameS’ and then switched to a single train df with ‘ColumnarModelData.from_data_frame’. However, I got the error with both setups.
I looked into the dataloader data, but this looks fine incl. dimensions (output of vars(md.val_dl.dataset)):
{'cats': array([[1, 1, ..., 1, 1],
[1, 1, ..., 1, 1],
...,
[1, 1, ..., 1, 1],
[1, 1, ..., 1, 1]]),
'conts': array([[-0.03765, -0.04689, ..., -0.1004 , 0.70786],
[-0.03765, -0.04689, ..., -0.1004 , -0.17852],
...,
[-0.03765, -0.04689, ..., -0.1004 , -0.16079],
[-0.03765, -0.04689, ..., -0.1004 , -0.17852]], dtype=float32),
'y': array([[ 13.79429],
[ 11.51293],
...,
[ 10.77896],
[ 16.1181 ]]),
'is_reg': True,
'is_multi': False}
I guess the 1s in cats array are a kind of placeholder for the embedding matrix?
For inspecting the data loader I used '‘vars(object)’ at several levels to get the objects. Maybe, there is a better way?
This is my code to generate the data loader and use it:
It is based on the rossmann notebook with parts from your kaggle kernel mentioned in the previous post. In the end its really not a lot of code, so I’m really wondering where the problem is located.
I don’t set the df index explicitly but this shouldn’t be a problem with a generic index (from 0 to len(df)-1)?
Thank you very much & best regards
Michael
I also tried to change the dtype of all columns to float32 but this ended in the same error.
I’m now at the end of my wisdom… any hint is highly appreciated.
(c, len(df_train[c].unique()+1))
Looks like a mistake. You are adding one before taking the length
Hello @bny6613
thank you very much, this is almost embarrassing but this was the problem.
Now I can start the learning rate finder.
Thank you very much for your help! 
Using Structured Learner for classification, is there a final resolution to how best to modify the rossman code to make it work? Thanks in advance for your guidance
Hello @datasciencegeek2018,
did you found a good way?
I’m currently playing around with data that has as y/target values ranging from 1 to 4.
Strangely, I can get the learner to run with out_sz=8 and not with 4 (leads to a cuda runtime error).
It seems that others got it working with the class sizes = out_sz, see: Problem with multi-class structured data learner and loss function.
I will/have to dig depper but I’m happy for suggestions. 
sorry, my focus has been on structured data for regression. Would be curious to know the same though.
I found my error after debugging for several hours!
Short story:
According to the pytorch docs for the NLL loss function you have to input the y classes like this:
(N) where each value is 0≤targets[i]≤C−1
So I recoded my classes ranging from 1 - 4 to 0 - 3 and set out_sz=4 which then worked.
Long story:
The output I got with y classes ranging from 1 - 4 and out_sz=8 was a softmax over 8 values summing up to 1.
I checked the MixedInputModel where the last (linear) layer is defined (self.outp = nn.Linear(szs[-1], out_sz)), but this looked fine.
Then I could narrow it down to the pytorch NLL loss function which was getting something which it could not handle properly (classes ranging from 1 - 4) and then interpreted that as 8 classes.
Now I can train my NN but after some time it seems to get stuck in a minima and is predicting the same class for all data points. After debugging is before debugging… 
Hope this helps somebody & best regards
Michael
P.S.: I found this for getting more meaningful information during debugging of cuda errors (from http://lernapparat.de/debug-device-assert/):
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
(Coincidentally, this article is showing a similar problem with the NLL loss.)
the fastai library now incorporates this since there is a parameter is_reg which can be set to False for classification and also modify out_sz to number of classes