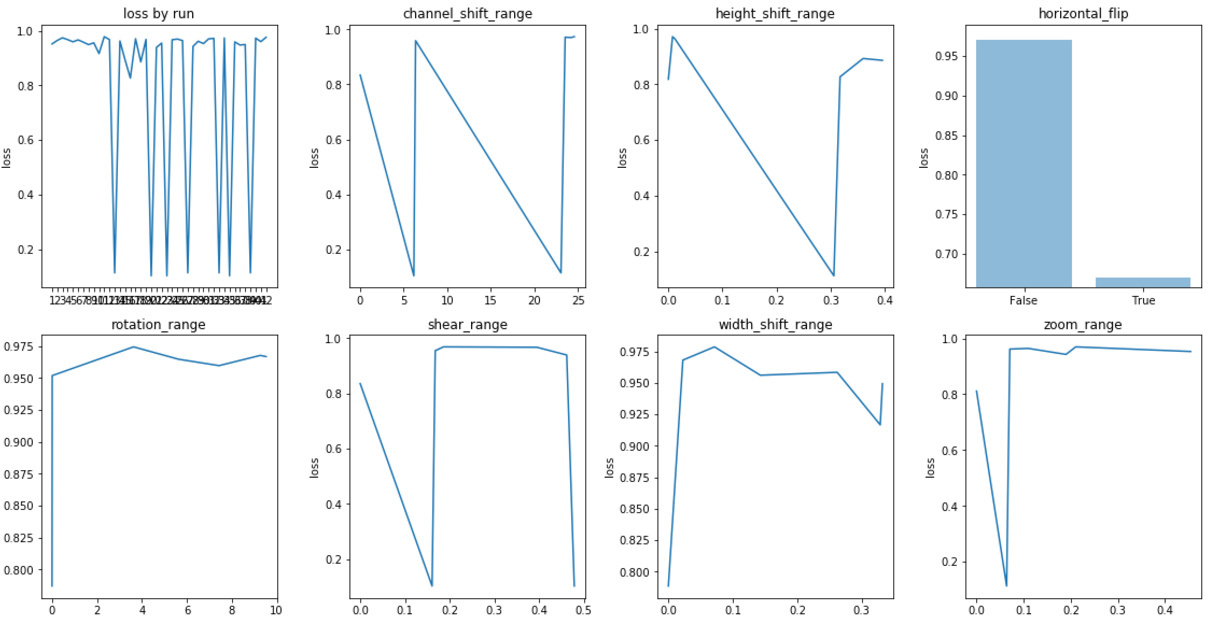
What optimisation strategies and packages do you use for tuning hyper parameters?
There is the brute force approach - gridsearch in sklearn. There is the univariate approach trying selected levels as @jeremy suggested for image augmentation. Both of these seem a bit manual and inefficient. I am sure there must be a better way.
I have been experimenting with scipy.optimize but not very satisfied with it and suspect my disatisfaction is more to do with the underlying algorithms than the package…these were the issues:
- One iteration means a function call for each parameter so when you have multiple parameters and a lot of data it has to do many epochs before you can break out.
- It goes out of bounds. You set a range of 0-2.999999 and a few iterations in it comes up with 3.00001. So now I have to check the bounds.
- Categorical variables are an issue. It generates a random float which I convert to an integer…but it figures the gradient between 2 and 2.6 is zero so gets stuck on category 2. I guess I could onehot encode it…but it is all adding complexity.
- Integers are also similar problem to categoric. You can convert a float to integer but this does not work…the algorithms see 2.1 and 2.9 (which were both floored to 2) as similar so they get stuck on 2.
Are there any good packages out there that automatically handle this in a simple way?