Very interesting paper claiming fairly big speed up.
Instead of just zeroing out activations at random like standard dropout, or zeroing out random rows and columns (and then gathering them back in a tensor) like Controlled Dropout, they just sample a contiguous memory block from the tensor and all other weights are ignored.
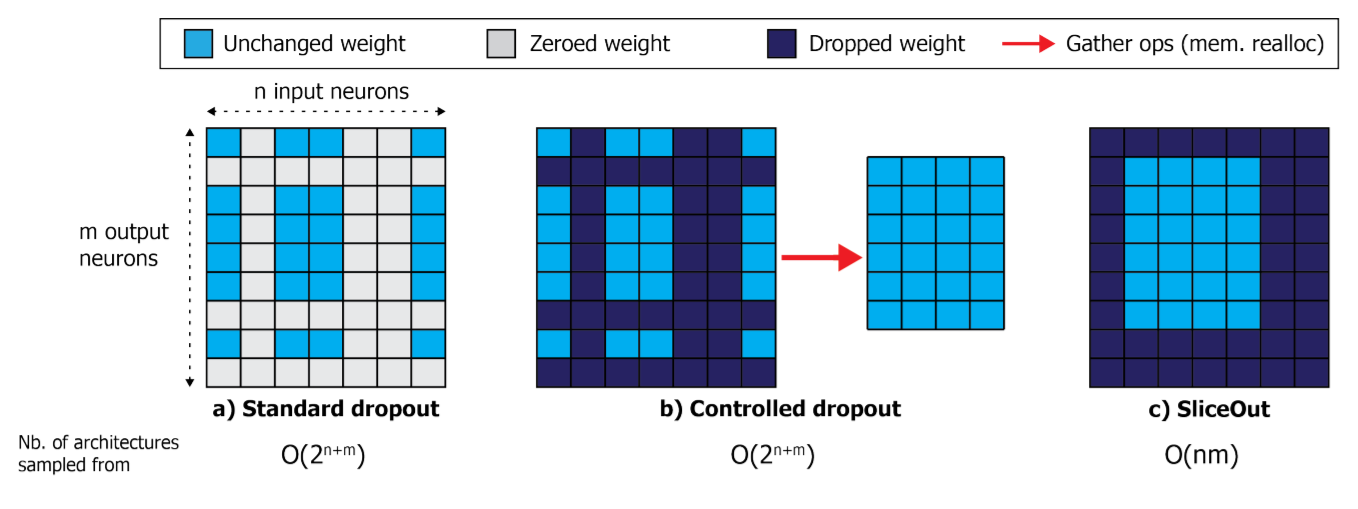
Relevant part of the paper:
SliceOut is a structured dropout scheme aimed at speeding up computations and reducing cached memory footprint, while preserving the regularisation benefits of standard dropout. We first convert the dropout rate into an expected number of nodes that should be kept at a layer where SliceOut is applied, i.e. the “slice width”.
During training, we uniformly sample the starting index of the slice (restricting to a subset of eligible positions as explained below), then “slice” (see next paragraph) the relevant rows and columns of the weights and biases that precede / follow the layer(s) where SliceOut is applied (Fig. 1). We then perform the forward and backward passes with the sliced weights and biases, updating the corresponding slice(s) of the original weight matrices in-place.
We repeat this end-to-end process, sampling different slices at each step, until convergence (see Algorithm 1). At test time, we use the full network without dropping any weights or biases, similar to standard dropout.