@Blanche, Was the pneumonia dataset a skewed dataset… i.e. very few instances of positive cases as compared to negative ones. If so then there are chances that the result will also be skewed. It will be really interesting to understand how to deal with these kinds of data.
Last year I took a deep learning course online, and I remembered one of the lecture was on skewed data but I can’t find it anymore. There was a medical image based challenge with a very skewed data set also. I would like to learn more about this topic.
2 Likes
This is very cool (as a fellow Trinidadian). President Max Richards was a Masquerader to the bone though (as a fellow Tribe band member), although I guess from the image he’s gotten classified as otherwise 
2 Likes
I also took a stab at using this dataset. I modified the Lesson 1 notebook and was able to get initially around 75% accuracy with Resnet34, but above 80% when using Resnet50 with fine-tuning. I published my notebook in this gist for anyone wishing to take a look at it.
1 Like
Fair point, but still there are 2x more pneumonia cases than normal lungs in data and it has 7x more errors, so I think there’s more to it thank skewed dataset. Maybe I’ll even the data out and see what happens.
This is the notebook for Distracted Driver Detection.
NB: inside you can find a generic starting code for kaggle competition, which integrates with fast.ai default folders and an example usage of DataBunch “from_list”, useful if you have to split train/valid by yourself.

12 Likes
@bachir
This is regarding your experiments on flowers dataset. Looking at your confusion matrix, you were training with random labels.
Your order of flower images (in fnames) and labels (from .mat file) is not the same.
In mat file, the label order is such that 1st label is for image_00001.jpg
So, you have to sort the fnames list.
fnames = sorted(fnames)
The above line of code before you create the ImageDataBunch will fix the ordering.
3 Likes
@bachir
Made a notebook for you!
Have a look at the confusion matrix and also the error rate during the first few epochs.
Hope it helps you 
4 Likes
Woohoo ! Congrats, this is superb result. Cheers ! Thanks for sharing the nb.
Hello!
I’ve tried to classify flowers using this dataset from Kaggle
It was great experience, the final result - accuracy is about 97.4% with resnet-50 architecture
I tried to learn incrementally with different learning rates for different layers, with checking optimal learning rate before unfreezing layers.
According to the most confused images, prediction has the biggest errors on data without flowers (because the data was gathered from internet), and it was good indicator I think.
You can find notebook here.
Do I understand correctly that if train loss is greater than validation loss but both decreasing including the last epoch, but error rate is the same for 3 last epochs, means that it is underfitted? Or maybe the reason is that this particular split on train/validation dataset can cause this behavior of loss values? Of course it will be better to use separate test set, but I decided to practice more on the topic of the lesson 1.
1 Like
was going through your notebook to understand how resnet18 was more efficient, when it caught my eye that you’re using the same data for both validation dataset and test dataset.
This doesn’t seem correct to me. If I understand this, validation dataset and test dataset should be different as per their definitions. The test dataset is used during during the training step, and validation is used afterwards to judge how good the training was. (Since test param is optional, I’m assuming fastai does this automatically in a neat way if not provided)
The idea is that, if the model were to see the validation set during training, it would then fit to validation set directly. This could explain why you’ve been getting superb results in a few number of epochs.
However, I’ll try to browse through the source to see how test parameter is used, so take my word with a grain of salt.

Perhaps @sgugger can clarify how the test param is supposed to be used, as I haven’t seen this used in course notebooks very often.
2 Likes
It’s the other way around, actually!
5 Likes
Ah, right, I forget this too easily. So, in that case, it is fine to load same data to both validation and test ?
I tried to follow the source but got lost a bit in DataBunch.
I was interested in doing voice recognition detection. I used Audacity (https://www.audacityteam.org) to trim the audio from the following clips:
- Ben Affleck’s speech in The Boiler Room (https://www.youtube.com/watch?v=JfIKzReNDF4&t=62s)
- Joe Rogan and Elon Musk Podcast (https://www.youtube.com/watch?v=Ra3fv8gl6NE)
And used 3 min 30 seconds of audio voice from each of Ben Affleck, Joe Rogan, and Elon Musk.
I used a 5 second sliding window to plot their spectrogram, using the tutorial outlined here: https://github.com/drammock/spectrogram-tutorial/blob/master/spectrogram.ipynb
Since there was roughly 200 seconds of audio, that gave me roughly 40 spectrogram pictures each of each person.
Here is a sample of the spectrograms for each class (I am not sure why some of them are warped - my original pictures that are uploaded are not warped):

Despite the warping of these pictures, I moved on anyways to see what will happen.
I trained it on Resnet34 over 4 epochs (default settings) and got roughly 60% error:

So I decided to go with Resnet50. The error rate improved to 30% over 10 epochs:
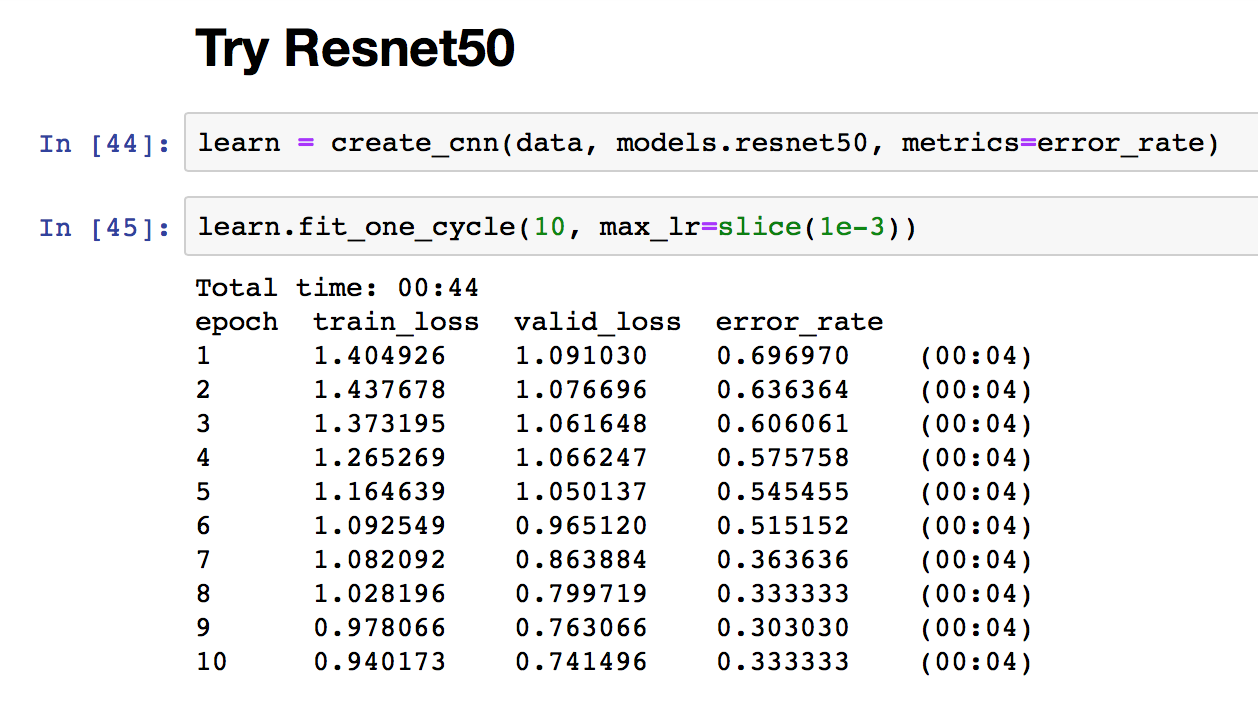
So, 30% is not quite as low as some of the other work that we’ve been seeing on here, but I’m quite pleased with the results:
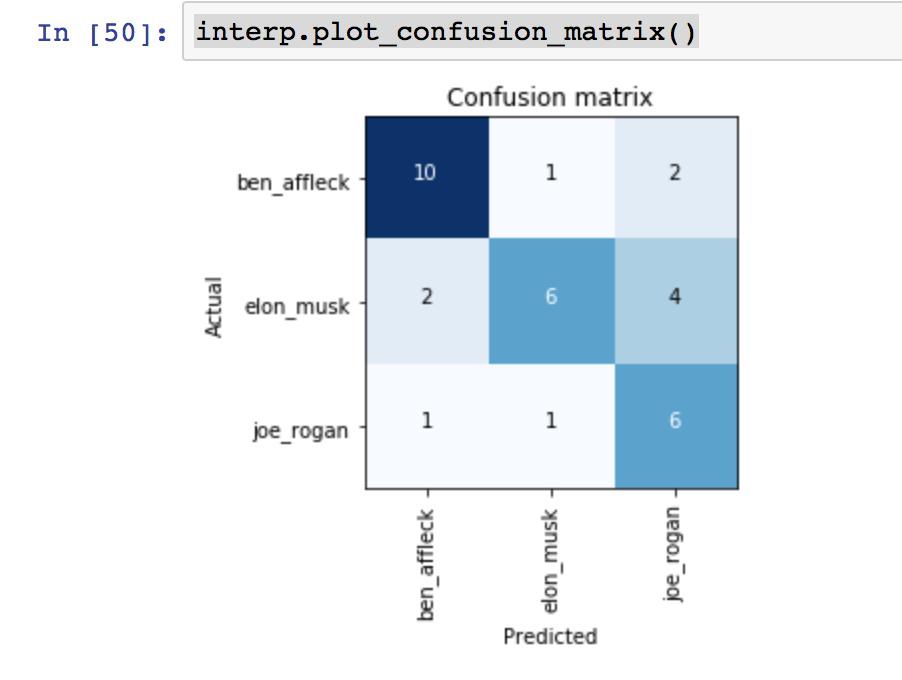
The model was pretty accurate with Ben Affleck and Elon Musk, while it was still better than random guessing for Joe Rogan.
I’d love to hear your thoughts on how I can improve the model. Obviously, I could add more training data - 40 samples each is probably too low (but this is a very tedious process to trim the audio to only a certain speaker and I might have run out of time for now). The warping picture issue is also concerning - not sure why that happened.
What do you think ? Otherwise, I’m pretty impressed that it did so well for Elon Musk and Ben Affleck for virtually zero tuning except to add epochs on Resnet50.
Because it did so well, I’m just convinced it will do much better on easier images  Those spectrograms look very similar to the human eye!
Those spectrograms look very similar to the human eye!
Thanks for reading this!
36 Likes
I was talking about RAM, since disk size is not a problem (you can attach many terrabytes, virtually any size). I also tried only 1% of the data since I definitely agree on redundancy argument. Thank you for your replies!
Hi Jeremy, thank you for your explanation.
I was probably confused by the fact that I got memory error (not GPU memory) and when I took a look at the code I’ve jumped to conclusions too quickly. Unfortunately, I lost my logfiles from that run, so can’t check now what was going there.
Did you try disabling transforms?
Thanks for the suggestion - no, how do I do that ?
From a discussion in another thread I looked at using activations to optimize an input and ended up implementing a deep dream sort of thing.

21 Likes
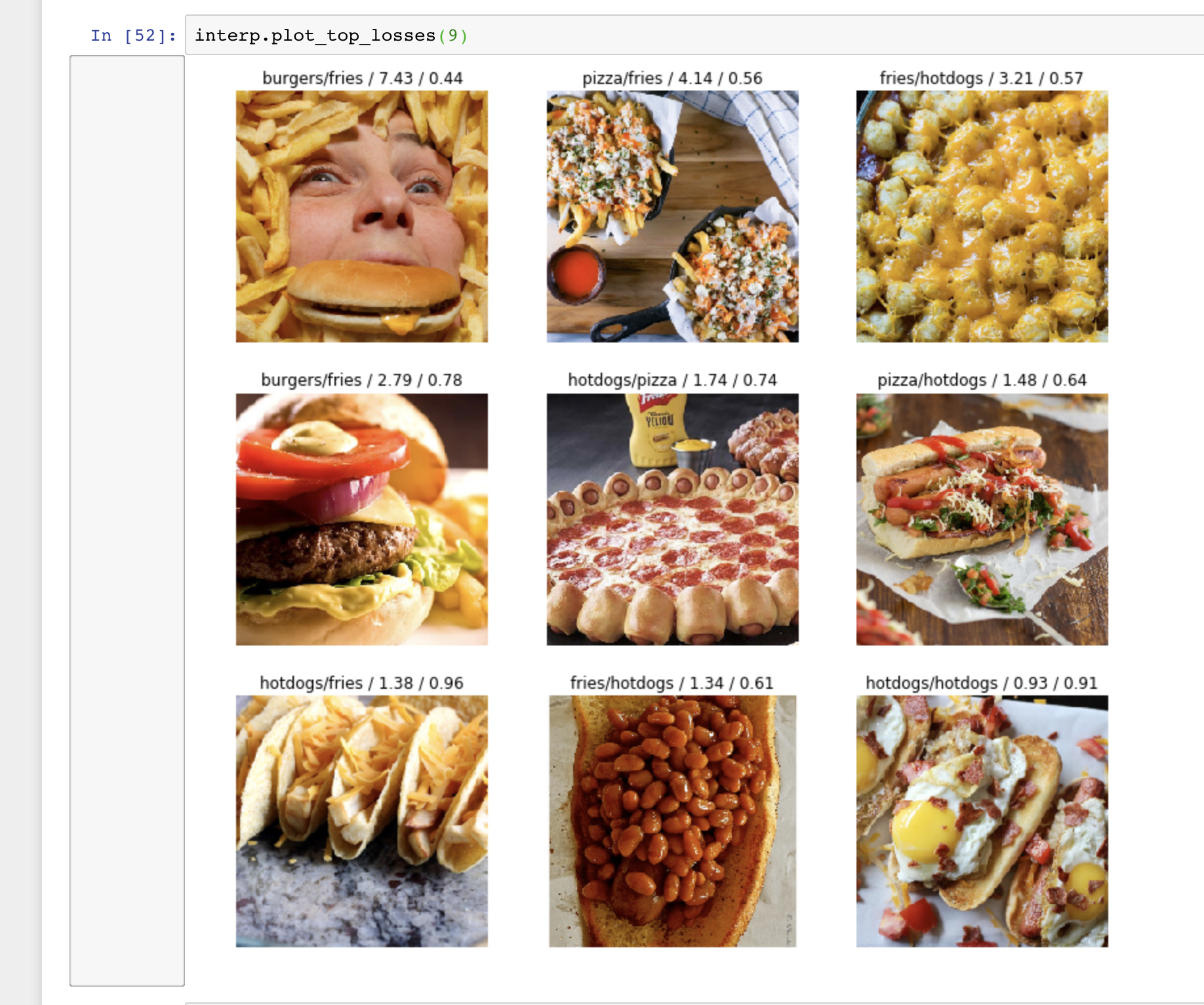
I used the course method for downloading images from Google to create a dataset of hotdogs, tacos, burgers, pizza, and fries. Must be time for dinner!
I got 94% accuracy right off the bat, with no cleaning/pruning of the data. I can see there are some errors in the training data. Here are the top losses. I wonder why it got #1 wrong? 
2 Likes