This is brilliant, thanks for sharing, so many great little tips and tricks!
Not sure if I missed it in the article but I’m curious if you think the Portuguese text is as good as the English text it can generate?
Also, is there much research on fine-tuning text generation models on different languages? I know cross-lingual models can help for translation, but I don’t think I had seen it for text generation before…
I’ve just released an update to fastinference, and two new libraries:
fastinference_pytorch and fastinference_onnx
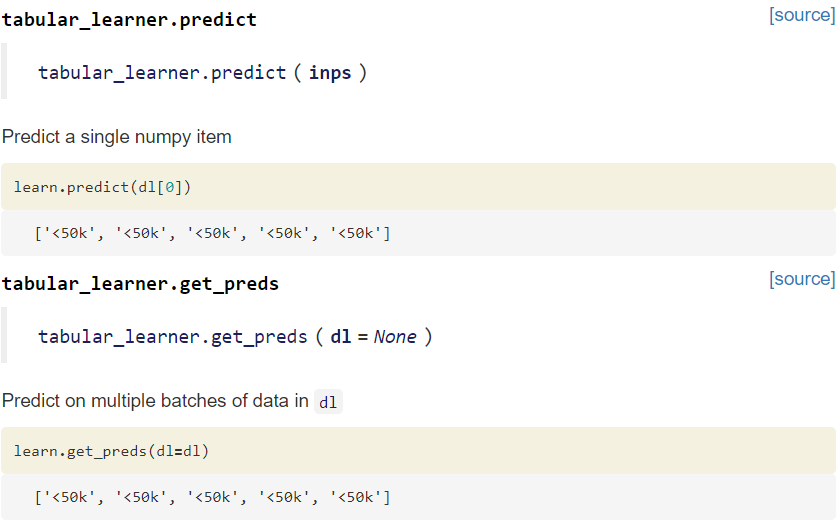
The goal of these two is to be lightweight modules to run your fastai models within a familiar API. Currently it just supports tabular models but vision and NLP are on the way! See below for a numpy example (there is zero fastai code being used )
Hello @morgan. Well, it was the objective of my work
Yes, I think that a small generative model (like GP-2 small) fine-tuned from English to another language like Portuguese allows to get a working model with a relatively small fine-tuning dataset (I used a bit more than 1 GB from Portuguese Wikipedia).
Well, great if I opened up some research but I’m sure there was already.
About applying the same fine-tuning method on encoder transformer-based models like BERT (RoBERTa, ALBERT, etc.), I’m currently testing my method on your FastHugs code. It works very well (because you did a great work Morgan!) I will publish soon.
I have been working on low light image enhancement using GAN and Perceptual/Feature loss. Got inspiration from Deoldify to try this up.
I will share the Github repo soon.
I have been researching the applications of CycleGANs (and related models) in pathology. I have written a paper that was presented at the ICML Computational Biology 2020 workshop:
I used fastai v2 and nbdev to accelerate my development. I collaborated with @ashaw and @danielvoconnor as part of the WAMRI initiative.
Recently, I have been working on refactoring my code into a package for unpaired image-to-image translation. Check it out here!:
Also, I will be presenting my research, talking about CycleGANs, and sharing code, TOMORROW August 28th 9am PDT:
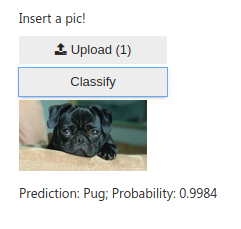
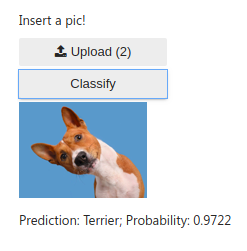
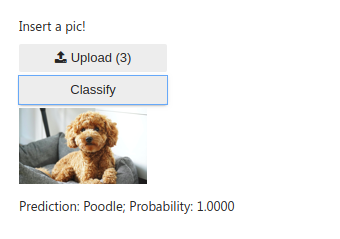
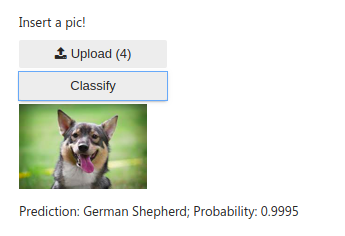
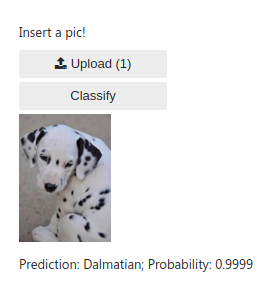
Made a very basic dog classifier based on the knowledge of Lessons 1 & 2. It can identify 17 different breeds of dogs. I used RESNET 101 architecture and 4 epochs with data set size of 150 images per breed to train the model with approx. 96% accuracy on validation set.
Hello all! I wrote a blog post describing a little bit of playing around I did with the movie review / NLP sentiment analysis at the end of lesson 1. Some surprises were found, e.g., the model thought ‘I disliked the movie’ and ‘I hated the movie’ were positive reviews!
How to identify ‘data drift’ a.k.a ‘Out-of-Domain Data’ a.k.a ‘is my test set distributed in same way as training set’, with image data, using fast-ai and alibi-detect.
Just a few days ago, a new (getting started) competition on unpaired image-to-image translation was launched on Kaggle. To demonstrate my package, I have made a quick kernel:
 )
)











 butterflies…
butterflies…