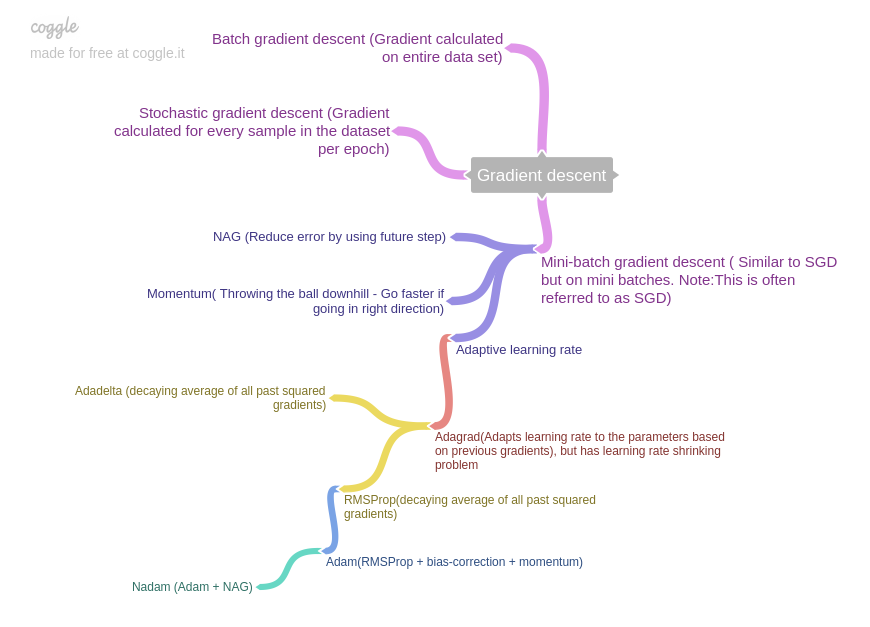
It seems like Nadam is the best. Although, we use Adam in most examples. Curious what you guys think about Nadam?
Also, I am a bit confused why is learning rate annealing helping with adaptive learning rate optimizations? Isn’t the algorithm supposed to handle that if it is adaptive?
Regarding your question on LR, I had the same thing in mind as to the necessity of annealing with adaptive learning rate. But I do know from personal experience that even with Nadam, using the ReduceLROnPlateau callback significantly reduced the error rate.