(Thanks for whoever posting the original script, I struggle for a day about the nvidia driver, this command install everything while creating the instance, perfect!)
Hey! I just created a script for GCP that should setup and get jupyter notebook running within few minutes.
Link - github
The mentioned steps are working for me. Please try and give feedbacks so that it can be improved.
Happy learning!!
I am doing local installation, and have managed to
(1) update NVIDIA driver to 396.24
(2) run conda install -c pytorch pytorch-nightly cuda92
and got output stating a version 1.0.0.dev…
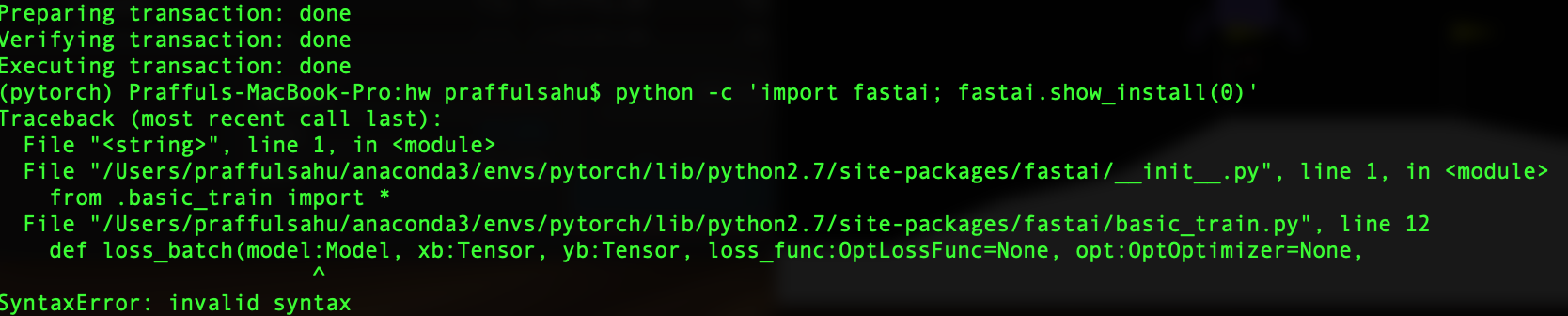
However, this piece python -c 'import fastai; fastai.show_install(0)'
now shows torch cuda version 9.0.176 (instead of 9.2). I don’t know whether this is what should have happened.
(3) Then I ran these conda install -c fastai torchvision-nightly conda install -c fastai fastai
…and the checks showed the correct outcome
However, when trying to run the lesson1 notebook, I get import errors. First on bcolz (which I installed with conda), and after that with cv2. It says ‘no module named cv2’.
Any guidance on what might have gone wrong, or is this to be expected?
Did you run into this error when running the lesson 1 (part1v3) notebook in colab?
@sgugger has posted solution although it will slow things down. I ran into the same problem which is Docker related and Colab is (I beleive) built on containers. I also posted a solution on the other thread but it is part of the docker run command and I doubt the “docker run” type of fix will help w/ Colab. It may be worth testing this and writing this into your Colab Guide if others are going to try and use it.
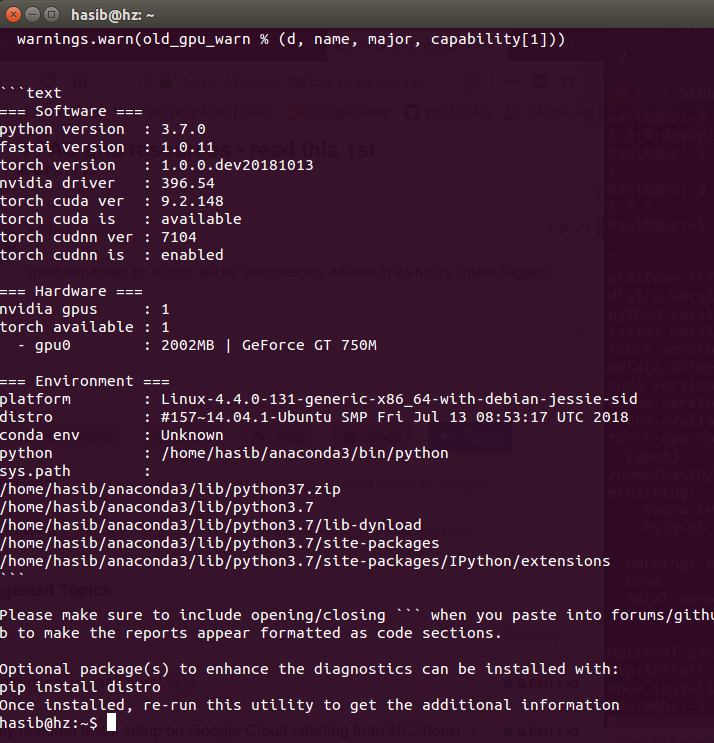
I’ve tried to update my local computer to fastai v1 setup. it’s seemingly working, I can train simple networks on pytorch using gpu, and e.g. the following looks sane:
python -c 'import fastai; fastai.show_install(0)'
```text
=== Software ===
python version : 3.6.5
fastai version : 1.0.11
torch version : 1.0.0.dev20181020
nvidia driver : 410.57
torch cuda ver : 9.2.148
torch cuda is : available
torch cudnn ver : 7104
torch cudnn is : enabled
=== Hardware ===
nvidia gpus : 1
torch available : 1
- gpu0 : 8119MB | GeForce GTX 1070
=== Environment ===
platform : Linux-4.18.14-arch1-1-ARCH-x86_64-with-arch
distro : #1 SMP PREEMPT Sat Oct 13 13:42:37 UTC 2018
conda env : fastai
python : /home/veehoo/.conda/envs/fastai/bin/python
sys.path :
/home/veehoo/.conda/envs/fastai/lib/python36.zip
/home/veehoo/.conda/envs/fastai/lib/python3.6
/home/veehoo/.conda/envs/fastai/lib/python3.6/lib-dynload
/home/veehoo/.local/lib/python3.6/site-packages
/home/veehoo/.conda/envs/fastai/lib/python3.6/site-packages
/home/veehoo/.conda/envs/fastai/lib/python3.6/site-packages/cycler-0.10.0-py3.6.egg
/home/veehoo/.conda/envs/fastai/lib/python3.6/site-packages/IPython/extensions
But when I try to use the fastai stack, there’s something that triggers an error in multiprocessing code. The following error comes when I try to execute ‘examples/tabular.ipynb’ from fastai github in jupyter. The error comes after executing the last command in the notebook:
...
learn.fit(1, 1e-2)
Exception in thread Thread-4:
Traceback (most recent call last):
File "/home/veehoo/.conda/envs/fastai/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/home/veehoo/.conda/envs/fastai/lib/python3.6/threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "/home/veehoo/.conda/envs/fastai/lib/python3.6/multiprocessing/resource_sharer.py", line 139, in _serve
signal.pthread_sigmask(signal.SIG_BLOCK, range(1, signal.NSIG))
File "/home/veehoo/.conda/envs/fastai/lib/python3.6/signal.py", line 60, in pthread_sigmask
sigs_set = _signal.pthread_sigmask(how, mask)
ValueError: signal number 32 out of range
Seems to me you’re not running the jupyter-notebook session in the right conda environment, so it’s detecting the host python and cuda installations and not the conda ones. Could that be the case?
RuntimeError: cuda runtime error (48) : no kernel image is available for execution on the device at /opt/conda/conda-bld/pytorch-nightly_1539431435477/work/aten/src/THC/generic/THCTensorMath.cu:14
yeah! thanks for feedback.
Actually i spinned an instance from marketplace-image of fastaiv1.0 + pytorch1.0 and then created an image of that disk attached to instance.
Marketplace images takes too long time to load and we need to install nvidia-drivers everytime, so i created the image and made it public so that it can be used directly. There is some error with the permissions of the image, i will check that out and revert to you.