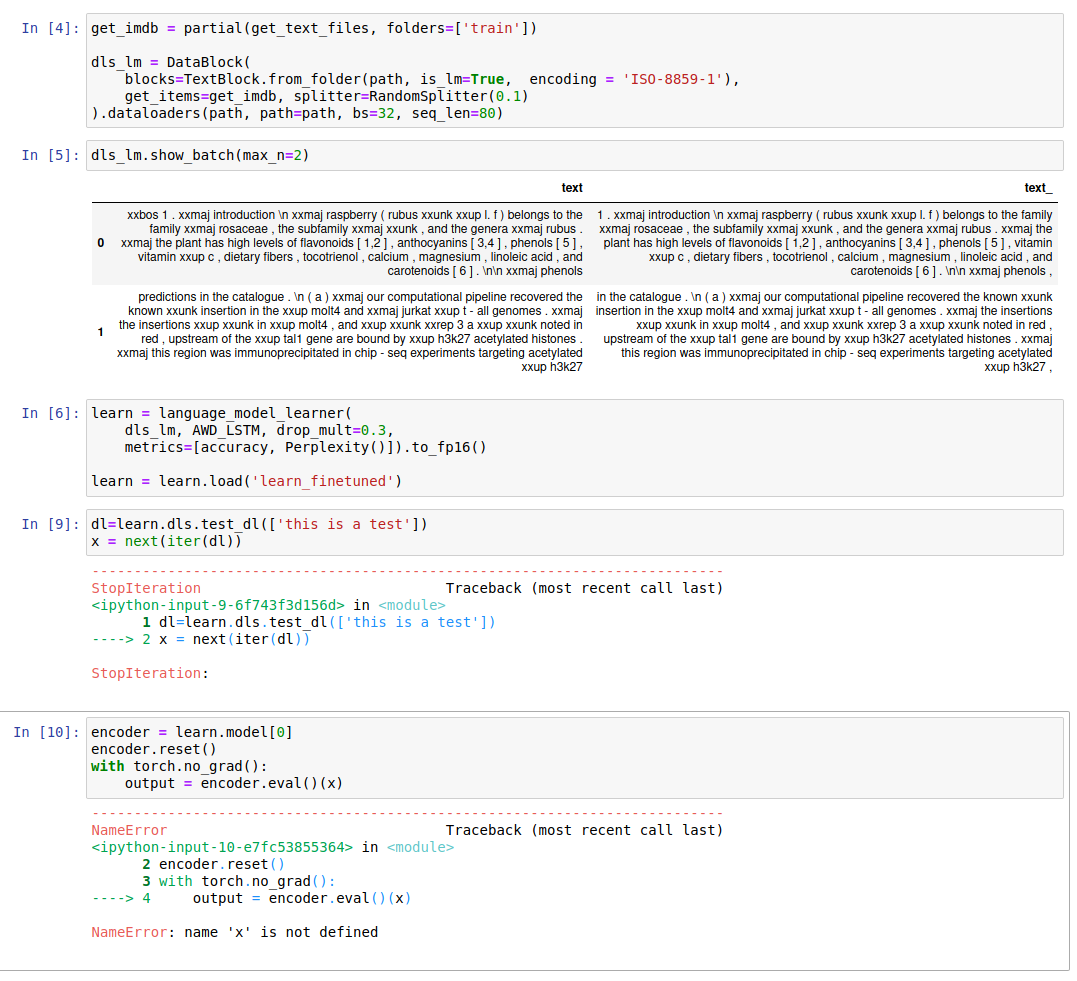
I use the following callback to extract the sentence embeddings. (I found the pooling functions here in the forums.)
def _masked_max_pool(output, mask, bptt):
return output.masked_fill(mask[:,:,None], -float('inf')).max(dim=1)[0]
def _last_hdn_pool(output, mask, bptt):
last_lens = mask[:,-bptt:].long().sum(dim=1)
return output[torch.arange(0, output.size(0)),-last_lens-1]
def _masked_avg_pool(output, mask, bptt):
lens = output.shape[1] - mask.long().sum(dim=1)
avg_pool = output.masked_fill(mask[:, :, None], 0).sum(dim=1)
avg_pool.div_(lens.type(avg_pool.dtype)[:,None])
return avg_pool
_pooler = {
'concat': masked_concat_pool,
'max': _masked_max_pool,
'last': _last_hdn_pool,
'avg': _masked_avg_pool,
}
class SentenceEmbeddingCallback(Callback):
def __init__(self, pool_mode='max'):
store_attr()
self.pooler = _pooler[pool_mode]
self.sentence_encoder = learn.model[0]
self._setup()
def before_fit(self):
self.run = not hasattr(self.learn, 'lr_finder') and hasattr(self, "gather_preds") and rank_distrib()==0
def after_pred(self):
feat = self.feat
hook = self.hook
first_epoch = True if self.learn.iter == 0 else False
bptt = getattr(self.sentence_encoder, 'bptt')
enc = hook.stored[0]
mask = hook.stored[1]
vec = self.pooler(enc, mask, bptt).detach().cpu()
preds = F.softmax(self.learn.pred, dim=1).detach().cpu().argmax(dim=1)
feat['pred'] = preds if first_epoch else torch.cat((feat['pred'], preds),0)
dec = learn.dl.decode_batch((learn.x,learn.y), max_n=len(learn.x))
dec_lists = list(map(list, zip(*dec)))
texts = dec_lists[0]
texts = [t.replace('\t','').replace('\n','').replace('xxbos ','').replace('xxup ','').replace('xxmaj ','').replace(' ', '').replace('▁', ' ') for t in texts]
feat['text'] = texts if first_epoch else feat['text'] + texts
feat['vec'] = vec if first_epoch else torch.cat((feat['vec'], vec),0)
if hasattr(learn, 'y'):
y = learn.y.detach().cpu()
feat['y'] = y if first_epoch else torch.cat((feat['y'], y),0)
def after_validate(self):
self._remove()
def _setup(self):
self.hook = hook_output(self.sentence_encoder)
self.feat = {}
def _remove(self):
if getattr(self, 'hook', None): self.hook.remove()
def __del__(self): self._remove()
se_callback = SentenceEmbeddingCallback(pool_mode='concat')
preds = learn.get_preds(dl=dl, cbs=[se_callback])
feat = se_callback.feat
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(feat['vec'])
coords = pca.transform(feat['vec'])