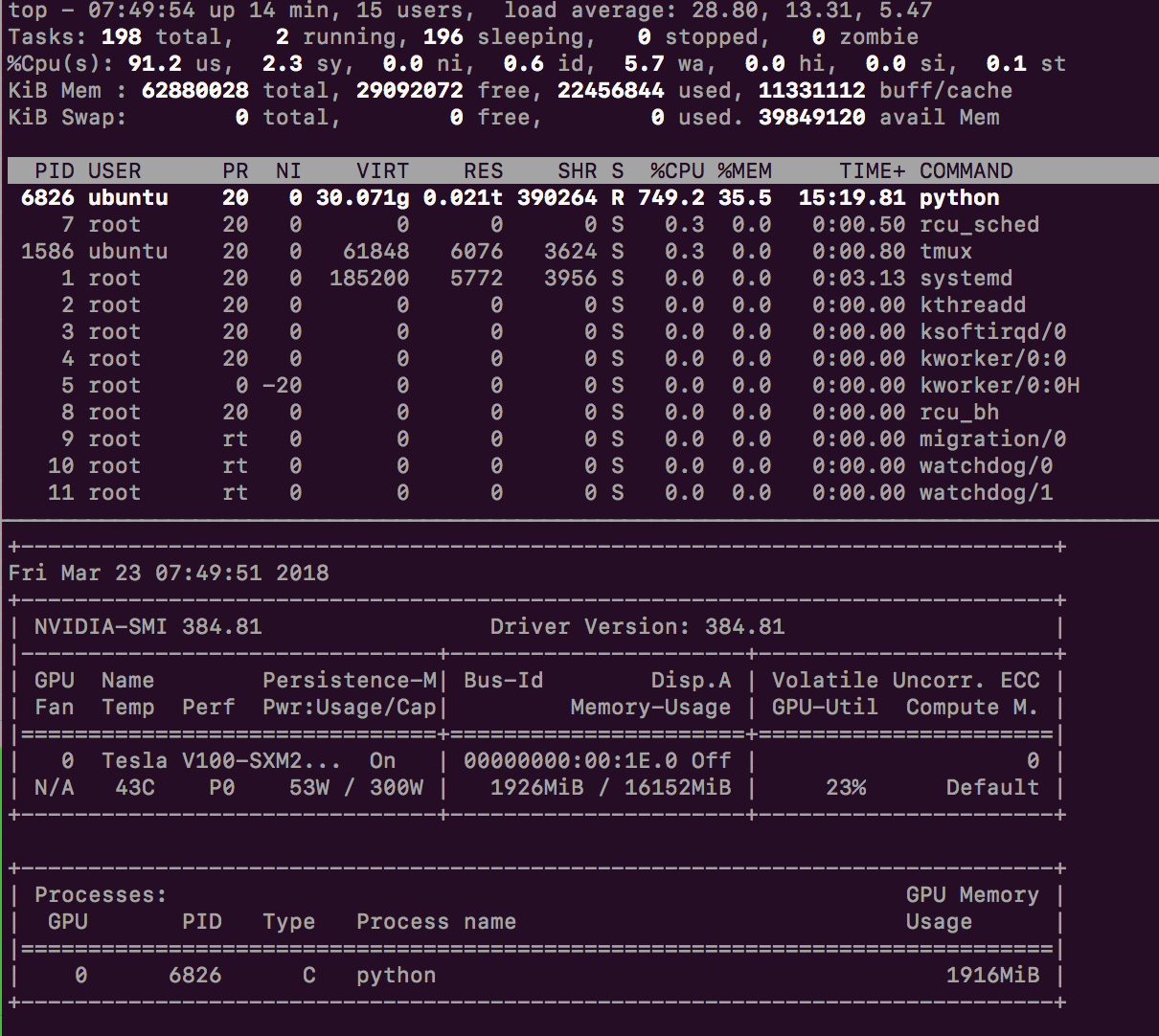
I am running on AWS p3.2xlarge (64GB RAM). I have a training dataset of 65000 images which are all at least 600x600 so the dataset is > 25GB. I am resizing them with augmentation down to 320x320. What I notice is that when the augmentation is happening, the memory utilization keeps increasing until the process crashes. I would think this is because the memory used by the augmented images is not being freed. I have looked in the source code but can’t yet figure out how where to fix this.
Have you tried reducing your batch Size?
For initial cycles of training you can also reduce the image size expected by the model. This will crop the image, so lose some of the image, but it will train much faster and use less memory. As your model starts to overfit, then increase image size expected, but this is when you may find you need to reduce the batch size.
I don’t think is batch size related, the augmentation is handled by a ThreadPoolExecutor with num_workers == n.
There is always the inital part of an epoch where the augmentation is done, then the GPU sits waiting for this to happen, so I increased the num_workers. I was using 30 (because there are 32 cores on that instance), the default is 8.
I would think the default of 8 was chosen for a reason because now mem utilization is staying constant at about 5%, at the expense of a slower epoch duration (all else being equal)
if I remember this well, data augmentation is done on the cpu (most likely via the opencv library), so def. not batch size related.
The easiest way to ask for help in these cases might be to gist the stack trace and paste the link here. Else, we will just be guessing.
The initial augmentation starts, then data starts to be fed to the GPU. However, as there is more augmentation always occuring, the memory usage jumps up, around 500MB every few seconds
This time around, I can’t reproduce it. 2 differences:
CPU utilisation never went above 800%, before it was at 2000%
Memory usage maxed out at 50GB
It makes sense this process would use a lot of RAM, however I would think it could release some as these are random image being generated (unless they are being cached so they can be resent to the model?). So it would be great to try figure this out and get the RAM usage down (for example if you had 2 GPUs on your own box with 64GB RAM, this would prevent the 2nd GPU being used)
@nextM did you resolve the issue?
did I understand correctly that with num_workers=8 there was low memory usage and with num_workers=30 memory exploded?
if that is the case, try find something in between. For my experiments I have modified fast.ai source dataloader iterator, but I am not sure yet it applies here.