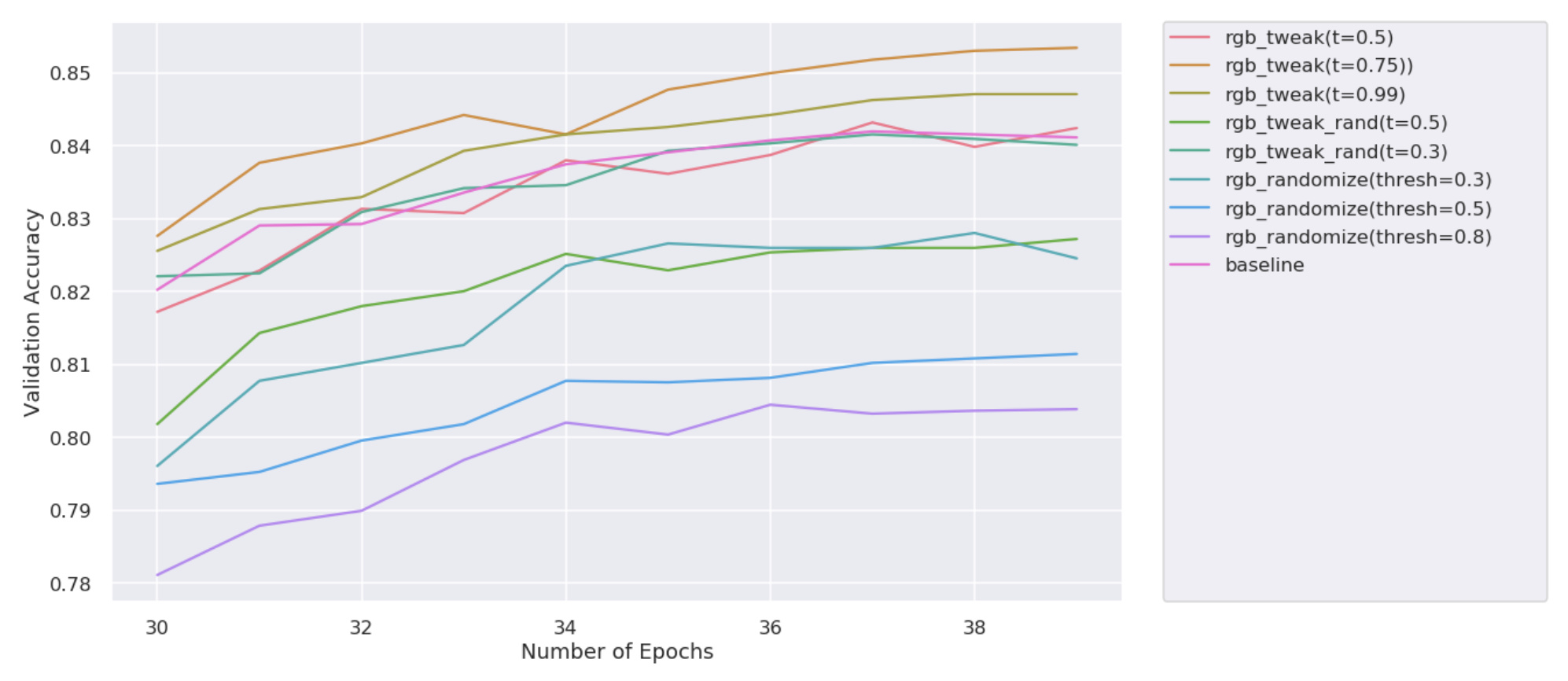
When you look at the source code for cutout in fastai.vision.transform:
def _cutout(x, n_holes:uniform_int=1, length:uniform_int=40):
"Cut out `n_holes` number of square holes of size `length` in image at random locations."
h,w = x.shape[1:]
for n in range(n_holes):
h_y = np.random.randint(0, h)
h_x = np.random.randint(0, w)
y1 = int(np.clip(h_y - length / 2, 0, h))
y2 = int(np.clip(h_y + length / 2, 0, h))
x1 = int(np.clip(h_x - length / 2, 0, w))
x2 = int(np.clip(h_x + length / 2, 0, w))
x[:, y1:y2, x1:x2] = 0
return x
It doesn’t say what type 'x' is. It seems obvious to me that this is an image, but I’m not certain how to find out if it is an image of 4 dimensions (batch size, rgb channel, height, width) or just (rgb channel, height, width)?
The reason I ask is because I’d like to perform a transformation on only one or two of the three channels. I think that removing one or two channels of colors would be a good addition to the list of data transformations. This is very much in sync with the ethos of fastai transformations
… that don’t change what’s inside the image (for the human eye) but change its pixel values. Models trained with data augmentation will then generalize better.
(Source: https://docs.fast.ai/vision.transform.html#_cutout)
To get a better idea of what I’m saying, consider the following images:
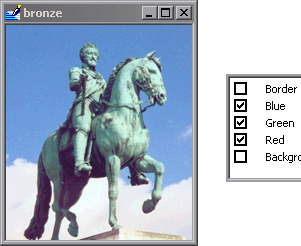
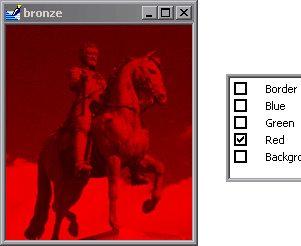
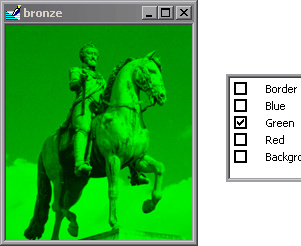

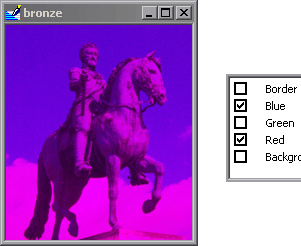
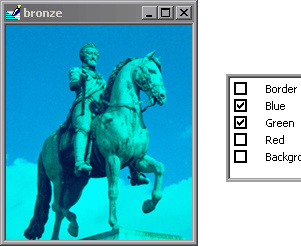
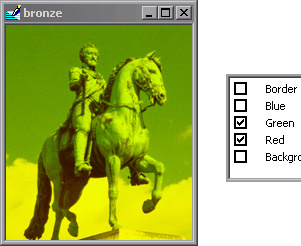
Sorry if this I’m repeating an already existing discussion (to the best of my knowledge, this is a new topic  )
)