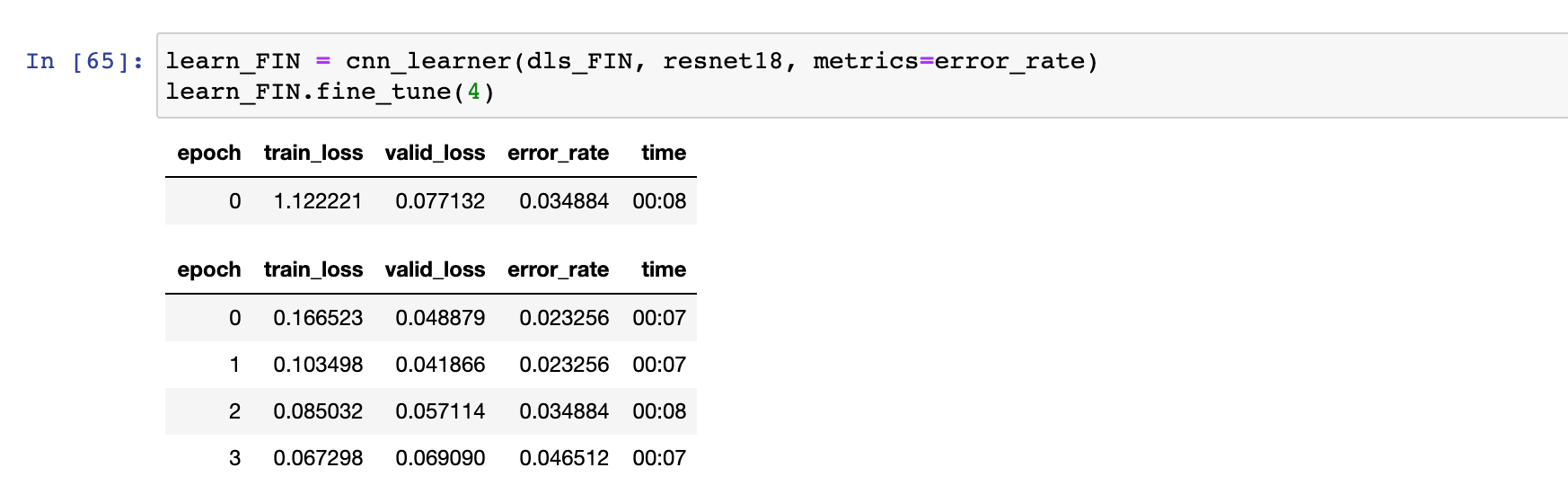
1)When you do randomresizecrop, does that mean each image is resized and cropped in four different ways ? so the total number of images seen by the CNN is 4 times the number of initially downloaded images? because i am seeing at 7:54 that the same image has 4 diff versions. if so, how do we set there to have 5 or 6 diff versions instead of 4?
-
Why didn’t we do the image resize in batch transforms if it is faster ?
-
I dont quite get why mult=1 and mult=2 in Aug_transform differ dont they pick the augmentations from the same possible set of augmentations that can be applied, so what does doing mult=2 really mean?
-
In plot top losses, when twe see images that were predicted correctly, what does
grizzly/grizzly/0.01/0.99 mean ? Does it mean that there is a p(0.01) that it picks grizzly correctly and 0.99 that it wrongly classifies the image? If so, how do we see what it would have predicted it as?
Also, training loss is what is used to feedback and optimise the model`s parameters right? and if so, does validation loss also do the same? if validation loss doesn’t help in optimisation, then why do we need to add error rate, wouldnt that have been already settled by the val_loss
EDIT: I rewatched the video and it seems like error rate is done to the whole dataset, meaning the full 450-ish images that we have.(totalled from the grizzly,tedd and black bear folders and disregarding the valid_percentage)
… could anyone clarify this, thank you