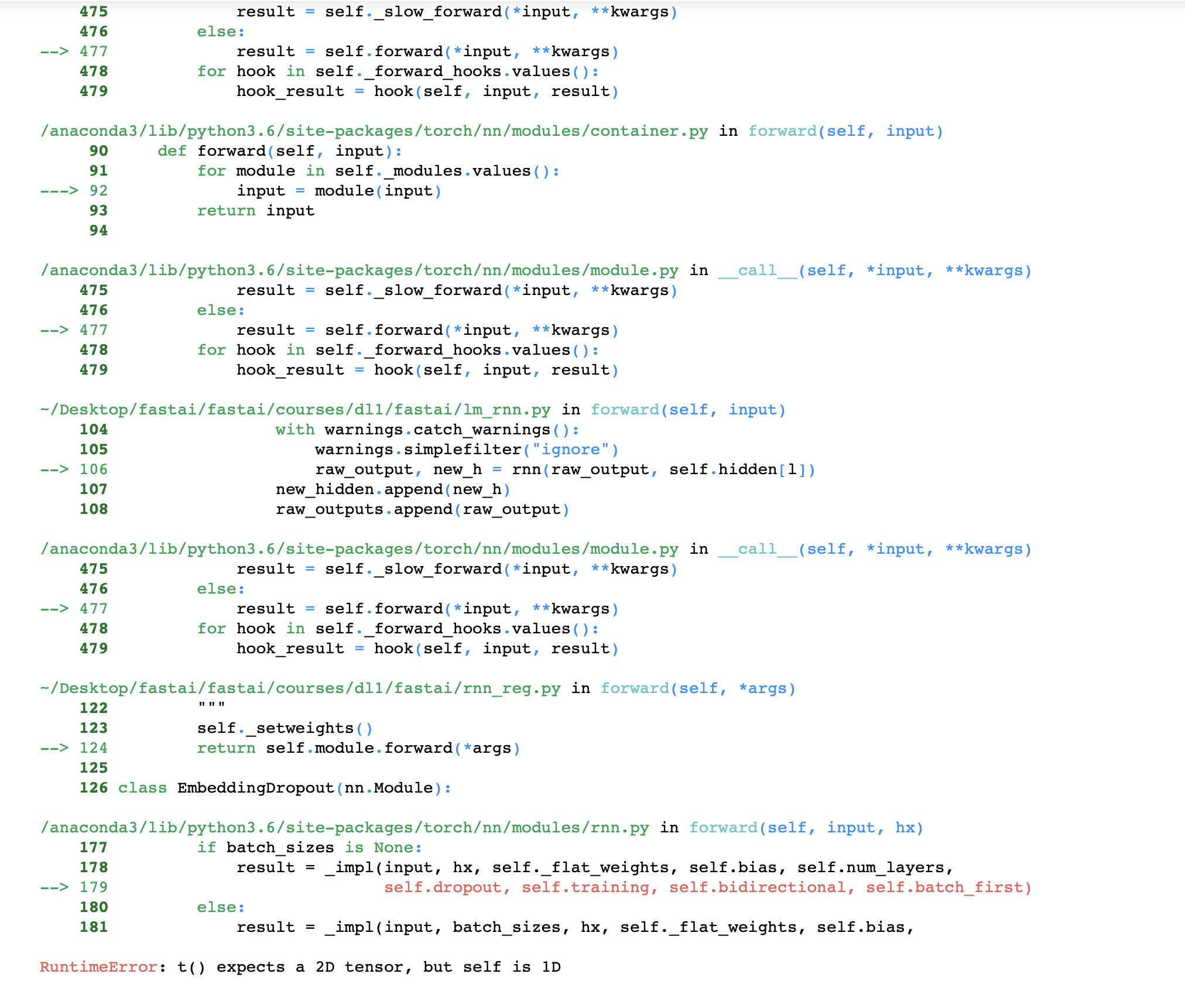
@zhye
tensor([[ 55, 2, 700, 2206, 6, 156, 4, 9210, 1221, 9,
4, 124, 261, 225, 159, 118, 6936, 294, 2, 58,
15, 1230, 121, 2578, 1365, 25, 4141, 3, 4, 671,
11, 472, 2, 1997, 331, 645, 5, 1246, 8233, 13,
6, 0, 17, 3327, 4, 2, 24, 7, 2, 2,
303, 27, 225, 8, 1241, 2, 6, 116, 8, 7,
1647, 8, 2, 4],
[ 887, 571, 65, 20, 59, 5, 4079, 4, 790, 3,
513, 1919, 376, 41, 244, 8, 11, 24, 14, 11,
11, 20, 36, 131, 11, 1684, 6, 374, 13, 7,
179, 136, 211, 10, 3671, 6, 5989, 5, 22, 29,
1049, 491, 2978, 10023, 1183, 73, 105, 2792, 7, 5559,
206, 71, 7, 2468, 38, 3, 3, 2, 2119, 23,
5442, 5146, 12, 2662],
[ 0, 9, 31, 34, 4, 510, 4, 34, 2, 1294,
3, 154, 9, 2, 236, 1330, 8319, 45, 268, 26,
5, 7, 40, 41, 1738, 47, 855, 30, 4567, 2575,
53, 36, 7, 2, 0, 3, 8, 2611, 773, 97,
12, 4, 2, 6, 600, 0, 7468, 9695, 6065, 8,
10, 2, 1518, 0, 5, 214, 20, 9048, 2, 22,
6, 7787, 1502, 422],
[ 7, 9765, 2, 3, 784, 2, 7, 3, 69, 6,
850, 2727, 6588, 6612, 95, 184, 12, 5, 26, 1472,
3837, 5, 4942, 24, 8443, 12, 7, 6196, 2, 2,
685, 3, 2, 5, 9, 783, 201, 18, 130, 325,
32, 9215, 1705, 10391, 22, 2, 1838, 160, 14, 1021,
2, 2562, 2, 13, 10083, 1171, 11, 2, 11, 11,
32, 4, 7932, 5],
[ 1652, 23, 0, 975, 7, 5, 2, 5096, 1955, 54,
8, 2, 4, 2, 2, 2, 4325, 5089, 84, 2169,
9, 529, 6, 14, 17, 84, 666, 2, 5927, 13,
2, 343, 3255, 2407, 23, 1047, 2, 1015, 758, 4269,
134, 4, 3735, 186, 4, 15, 7266, 38, 1270, 7,
21, 308, 2461, 4618, 10, 42, 1731, 3, 170, 614,
41, 2, 4, 1569],
[ 3712, 7941, 6, 837, 2663, 892, 903, 6, 2, 9491,
0, 88, 13, 94, 213, 94, 60, 2487, 994, 317,
128, 8, 98, 665, 3, 526, 147, 5097, 2, 5,
5617, 6, 93, 184, 6675, 16, 130, 2140, 5, 9,
2, 3737, 2728, 21, 2, 1008, 2, 577, 2120, 82,
0, 27, 18, 1824, 2, 1611, 6838, 575, 9, 15,
46, 15, 394, 6],
[ 2, 7647, 7391, 6, 2, 0, 115, 156, 16, 251,
496, 11, 158, 13, 6, 11, 7158, 479, 6, 368,
2109, 128, 73, 119, 8754, 487, 2, 11, 1985, 1625,
0, 799, 2, 7, 2, 21, 43, 41, 77, 0,
3, 4, 2, 2491, 3935, 9, 1931, 210, 7, 78,
2, 30, 15, 4, 3, 1076, 1069, 2, 820, 2,
390, 75, 8452, 2240],
[ 15, 11, 2, 802, 155, 18, 960, 1378, 505, 2,
10, 328, 78, 658, 320, 145, 30, 14, 1527, 3,
1821, 2, 2, 15, 3841, 1047, 5, 2, 7, 9838,
47, 5, 610, 0, 13, 40, 2, 2, 176, 2,
1879, 3451, 347, 17, 9, 25, 621, 2, 2, 184,
5, 220, 169, 2708, 0, 10, 9, 2643, 308, 893,
18, 29, 4, 1153],
[ 126, 5313, 13, 116, 537, 3, 7, 10, 16, 10013,
2, 2, 7, 6, 8572, 273, 38, 2, 2, 2047,
12, 16, 5, 84, 1559, 12, 10187, 4899, 385, 6,
6, 8378, 177, 160, 46, 8, 119, 5, 2076, 1833,
6, 4, 3, 3, 3, 188, 2174, 10104, 945, 2,
2890, 83, 15, 4, 6, 2, 3096, 2, 318, 3,
5, 85, 7, 2],
[ 35, 204, 755, 10, 448, 0, 950, 2, 3847, 2,
9082, 4, 1574, 632, 14, 3995, 61, 75, 680, 8,
5, 1652, 3348, 172, 1883, 3, 5709, 4, 2, 3973,
3, 4908, 2, 2, 9225, 9064, 21, 319, 8, 15,
2860, 3921, 252, 460, 774, 7038, 2139, 7, 2, 6,
853, 230, 2683, 7, 4645, 6073, 165, 77, 12, 232,
8264, 18, 2467, 10830]])
first 10 rows somewhat look like this!!!