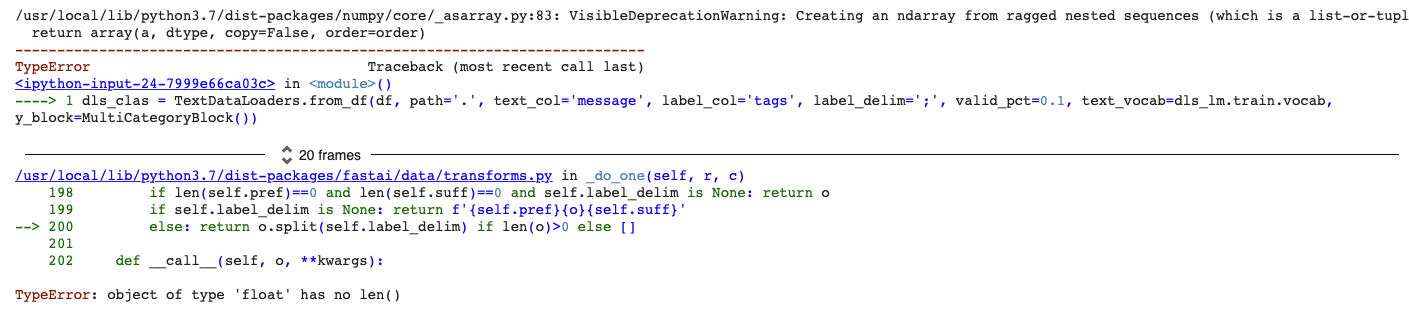
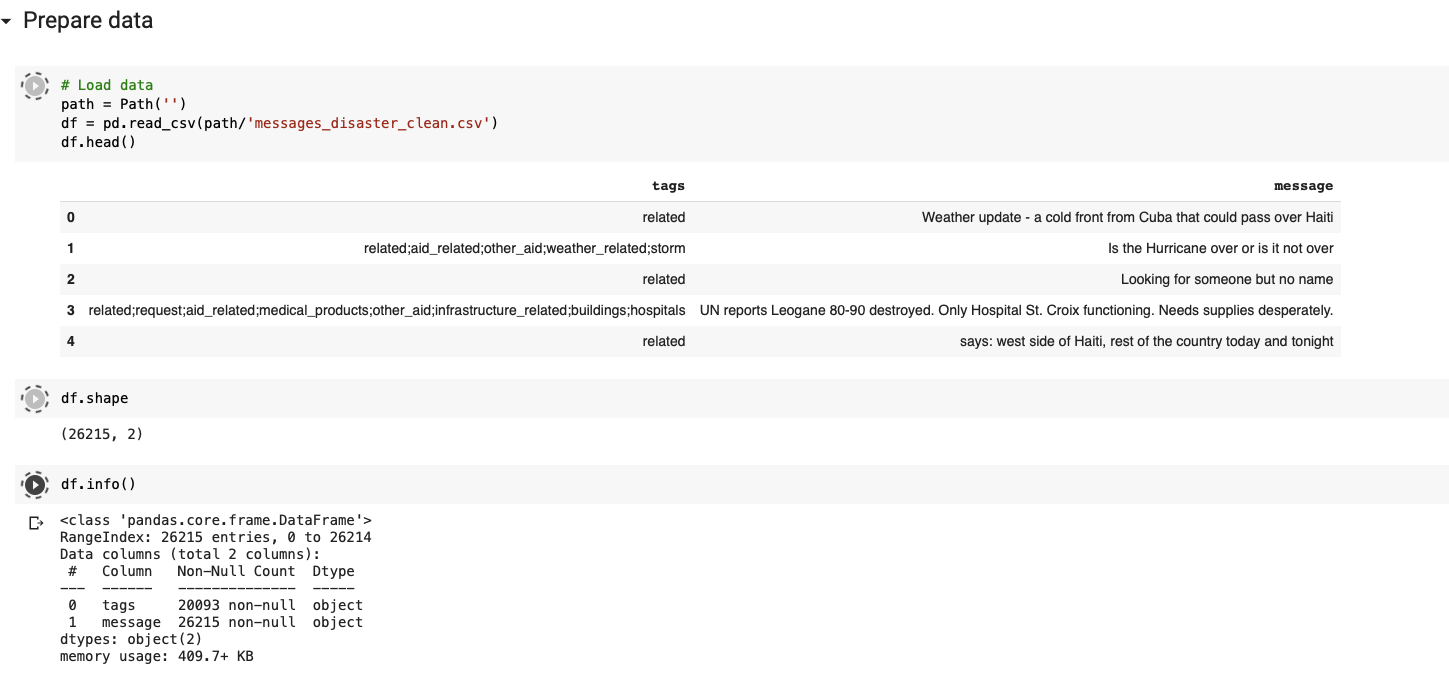
Hi there. I have been trying to create a text data loader using a language model I trained earlier. The labels are multi category, from a data frame with a ‘;’ delimiter. I’m getting these errors and having a lot of trouble trying to figure out why! Can anyone advise me?
HI thanks for your reply. Yes I have attached details of the data frame. What do you think could be the cause of this? The language model for this data set gets created fine?
Thanks for your reply. Yes there were nans/null in the labels. I removed these and remade the data loaders but I still got the same errors? so it seems the nans was not the issue?
Then there must be some more float variables in the dataframe.
A quick hack to remove all floats from the df could be: df['tags'] = ['' if isinstance(x, float) else x.split(';') for x in df.tags]