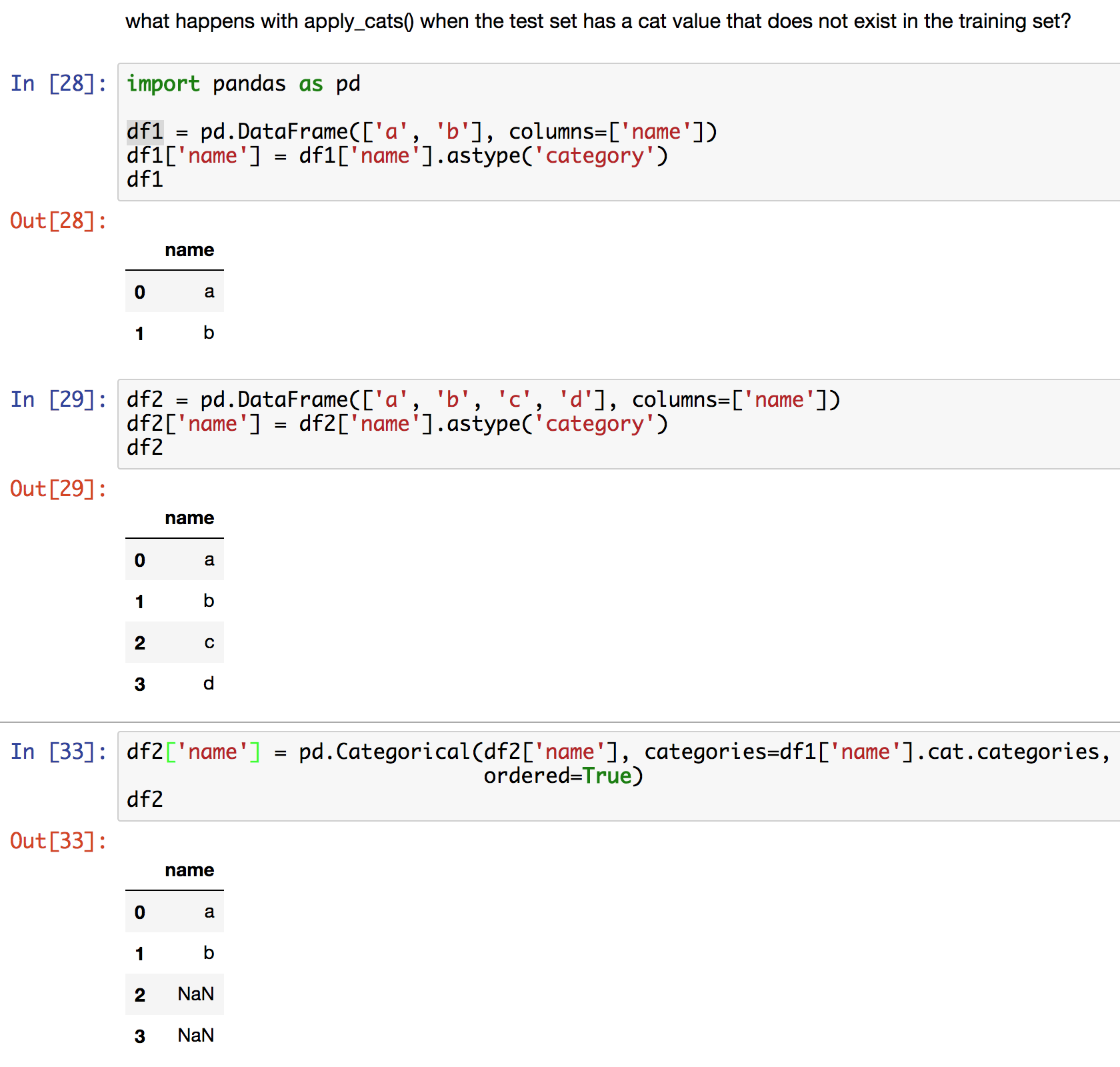
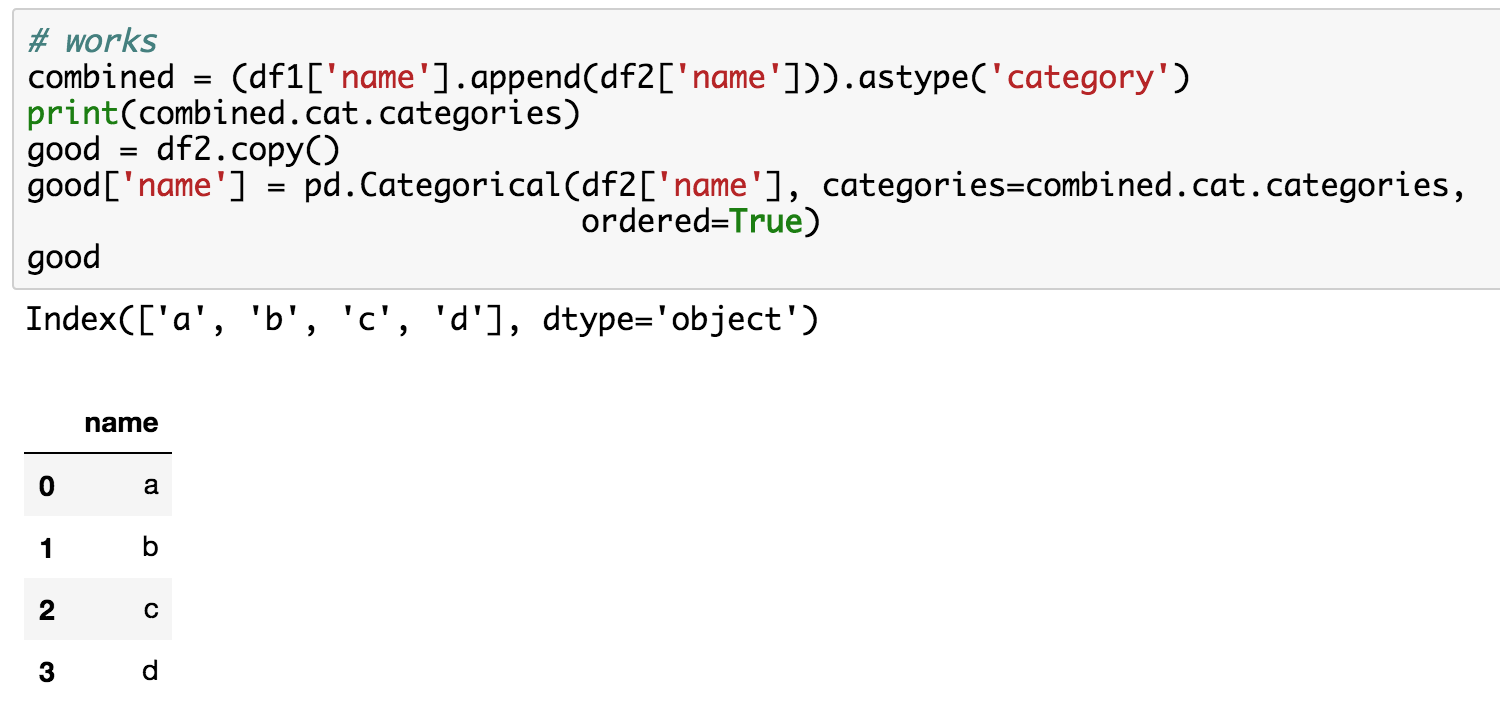
@jeremy, I am trying to transform test data based on the transformations train_cats( ) and proc_df( ) done on training data.
Similar to apply_cats( ) for train_cats( ) what is the applicable transformation with proc_df( )?
I was just wondering, looking at apply_cat( ) it seems that you need to pass both the train and test data. In a case where a test data is comparatively large as the train data do you think this function is efficient (my AWS instance got stalled due to this)?
What is the best way to get rid of a situation when AWS instance get stalled due to a memory issue when running a large data set?
Btw I figured that AWS instance got stalled not due to the apply_cats( ). Apparently converting numerical (int, float) columns to string type columns in a large panda data frame is expensive.
I was using (cat col refers to columns I want to convert to strings)
df_test[cat_col] = df_test[cat_col].astype(str)
Above result in memory issues
This works better
for col in cat_col:
df_test[col] = df_test[col].astype(str)
This is probably what you want. If you include categories that aren’t in the training set, they won’t appear in your RF, which can lead to odd results.
You still use proc_df, since now that you’ve got the categories set up, you don’t need different logic for the test set. You can just add a column of zeros to be your ‘dependent variable’ since for now proc_df assumes there is one. Better still, edit proc_df to make the dependent variable optional, such that if it’s not provided as a parameter, it’s not removed/returned - and then submit a pull request to the fastai repo so everyone will benefit!
Probably reboot using the AWS console, if there’s so much memory pressure you can’t even use ssh. If you can use ssh, just check top to see the proc id of the bad process, and kill -9 it.
Thanks Jeremy, I actually used proc_df similar to train data with a zero column after posting my question. One concern area was now we will be using test data median for imputation rather the train data median. I guess this is just a minor consideration?