Hello everyone.
I’ve done some work on reproducing the results of the first part of the paper Distilling Task-Specific Knowledge from BERT into Simple Neural Networks.
The code is at https://github.com/tacchinotacchi/distil-bilstm.
The first part of the paper focuses on training a tiny BiLSTM model using a training objective based on imitating the output of BERT for the SST-2 sentence classification dataset.
I think I can say I’ve successfully reproduced their results, although I’m getting 1 to 2% lower accuracy than reported in the paper across all methods.
I think it would be neat if it was possible to reimplement the same workflow in fastai, and it would probably allow me to obtain better performance thanks to all the tools in library, like the lr finder.
The workflow is based augmenting the original dataset, then using a teacher model to generate the labels for the augmented dataset:
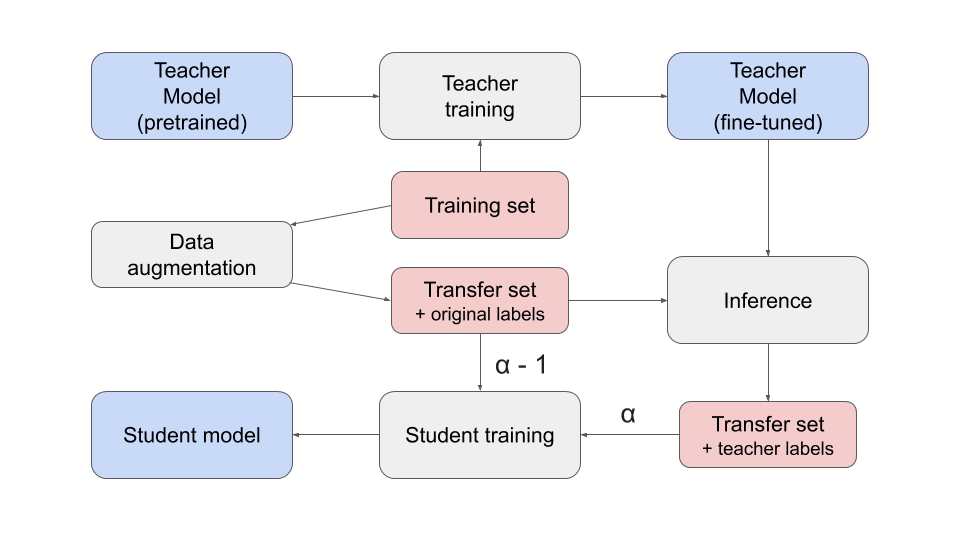
(alpha is the weight of the loss function w/ respect to the teacher labels. In this case, alpha equals to one as the original labels are untrustworthy.)
How do you think this can be made to fit in fastai? I think the best way, especially for small datasets, would be to write a Databunch class that can load the sentences along with the scores given by the teacher for each class.
In my code, I use the .tsv format in this way:
This movie was disappointing<tab>1.23 -0.456
As you can see, the scores for the different classes are separated by whitespaces. How would you go about loading this dataset in fastai?
Thank you if you got to the end! It’s ok even if you just tell me to go RTFM, all tips are well-received 