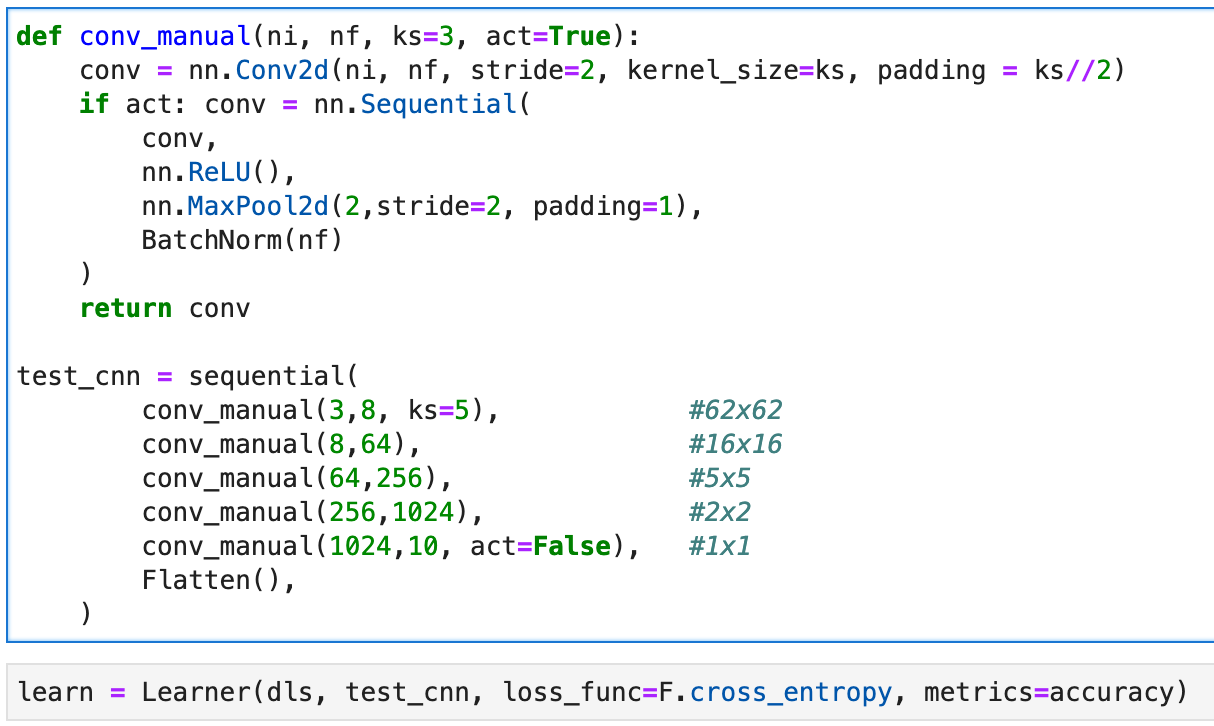
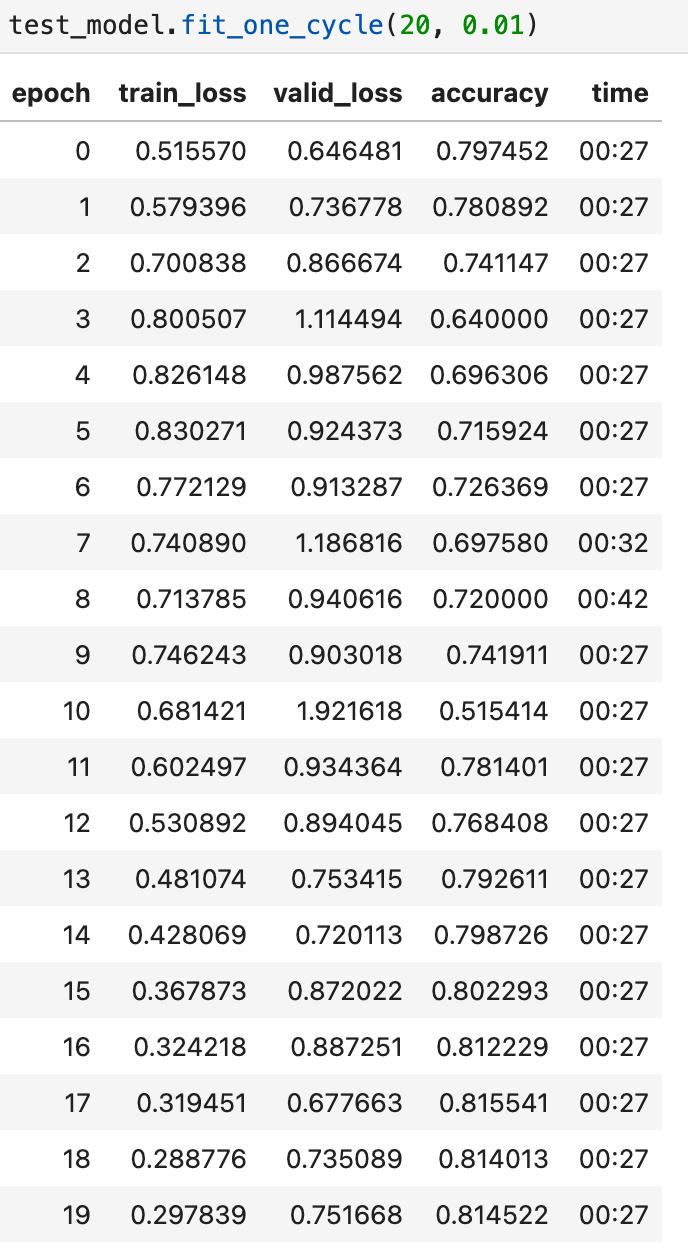
I’m currently practicing what I learned in Lesson 13. I built and trained a CNN for ImageNette set. I applied pooling and batch normalization to it. Here are my model and result (20 epochs with max_lr = 0.01). I used 1cycle for the training.
I noticed that the result/accuracy seems to be around 80% at max. This is different from the one in Lesson 13 with MNIST dataset. The model in that lesson did not use batch normalization but was able to get 98% accuracy with just 1 epoch training.
Is it accurate to say that my model performed worse because the dataset I’m working with is more complex (color image with different object compared to just BW image of numbers of MNIST)?
Or is my model not well built and it is missing something? I could not get the result to go above 80% even with batch normalization.
Hello, Toan
Have you tried playing around with the learning rate? Overfitting seems like a possibility. Additionally, could you have applied your normalization to the training set but not the test set? Those seems like the two possibilities that immediately come to mind.
Perhaps this thread on stackexchange will help? It seems similar to what you’re experiencing, although your validation loss seems to be randomly fluctuating instead of going up.
As you pointed out, it seems that I have an overfitting case here. I’m not sure why. I did not use any normalization method for my data (expect batchnorm for layer’s input).
My apologies if this bothers you. I just hope to hear more of your thoughts regarding my case.
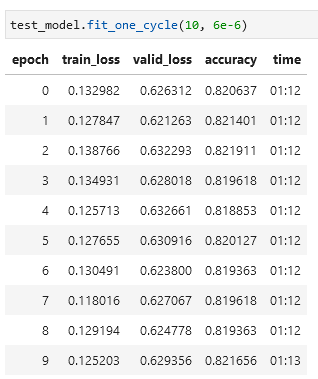
Following your advises (overfitting issue and playing around with learning rate), I have tested my model with different techniques like Label Smotthing, Mix Up, Data Normalization and different learning rate. All of them helps the training to converge faster (especially with data normalization). But the result seemed to be maxed at only 82%.
I decided to increase my model’s size (from 2 millions parameters to 182 millions). My assumption is that bigger model could potentially make better predictions. But the result still capped around 81% after 50 epochs.