As instructed at the end of Lesson 3, I am trying to do as many Kaggle image competitions as I can the next few days. My first one out of the gate is the Invasive Species Monitoring competition. Similar to the Dog Breeds example, this one uses a csv and has a train and test dir with images.
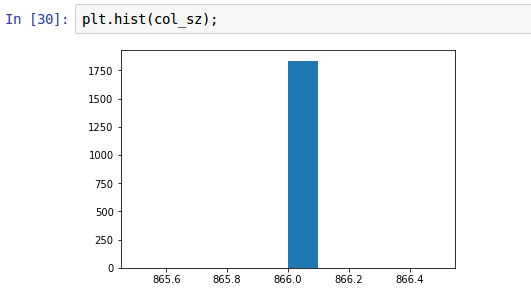
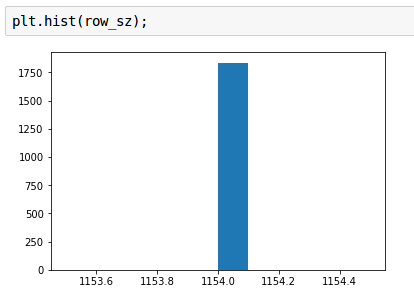
My question is what to do when the image size is unlike what we have seen in the first three lessons. These images are all ImageNet ‘type’ images, but their resolution is 1154x866 (not even in the realm of our ImageNet trained examples).
There is no simple answer to this question. The canonical approach would be to resize the images. But you might want to experiment with other approaches, including center crops, random crops, etc. This will depend on whether there is a main subject in the image, where it is positioned, etc.
As a rule of thumb, you might want to first go down the path that would allow you to build a functioning model the quickest. That probably would be resizing the images to more reasonable dimensions or center cropping. Once you have something in place that trains and that you can use as a baseline, you might want to experiment with other approaches and see how they do.
Thank you for your guidance on this. It is very helpful. If I may ask a follow up based on your response. Assuming resizing creates a decent functioning model, would it be a good idea to try other approaches (center crops, random crops, etc.) as part of the dataset? That is, adding it to the existing resized images dataset? Or does that cause overfitting as they are the same image? I assume based on the incremental resizing technique Jeremy showed in Lesson 2 (1:33:00) it will not harm the model, but thought that I would ask…
If I am understanding correctly you are considering adding multiple versions of the same image with various alterations? For starters, you would go only with resized images but should you be able to get this to work well you might add center crops, random crops, etc?
I don’t think that this should be an issue. Hopefully via seeing more versions of the same image your model will learn to generalize better. This is precisely the idea behind data augmentation - we manipulate the images available to us to artificially make it seem as we have more data. The nice thing with data augmentation is that it is done on the fly and can be done randomly across multiple parameters - we might chose to alter other parameters of our images, such as hue / saturation / rotation, horizontal flips etc.