Hi All,
Running the same dataset on paperspace and a local GPU (running paperspace docker image from github) yields dramatically different results. This has not always been the case, and only changed in the last two days. Incidentally, trainings like dogs and cats converge similarly on both instances.
The paperspace training converges nicely resulting in an error rate of 0.030362 and a validation loss of 0.077516.

Running the same training notebook on the local GPU results in the model diverging, and almost all validation set predictions in the same category.
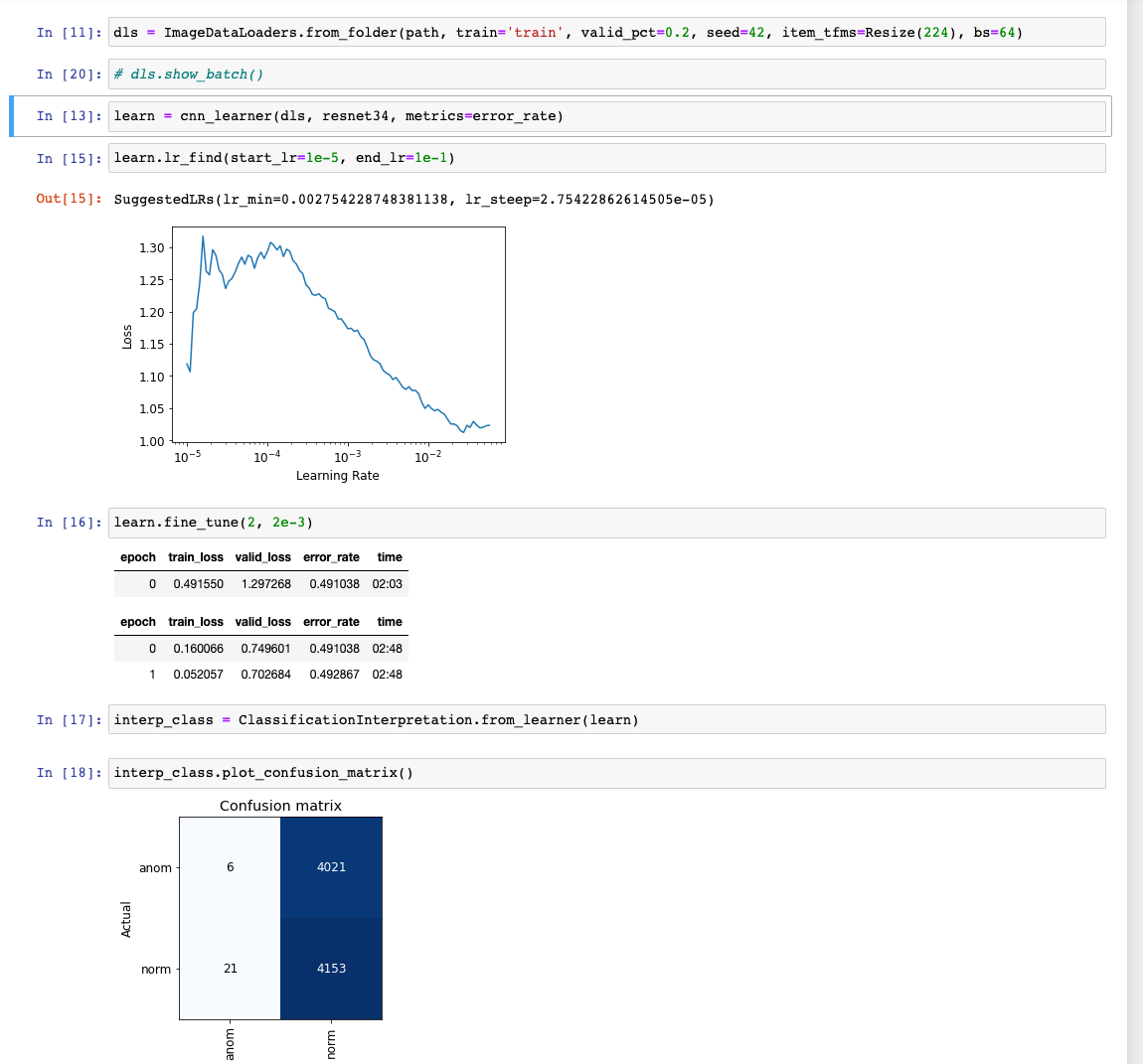
Note the different starting validation losses in the two cases as well.
Things I’ve tried so far:
- Complete rebuild of docker image
- Removing all data and notebook directories and restoring only the training data and .ipynb files.
- Training resnet18 on both instances yields the same result
- I would love to try training one fine tune on the paperspace instance, transfering network to local GPU and fine tuning one more epoch. I cannot figure out how to export the optimizer state and re-link the image data loader.
- Looking at the mean and standard deviation on each instance shows that they are remarkably different. E.g., on the paperspace instance the mean and std of one batch (either valid or train) is about -1.08 and 0.69 while on my local GPU it is 0.20 and 0.14. Perhaps this explains the difference in initial loss after the first freeze epoch.
I am at a loss as to what to do next or where to look. Please let me know what you think I should try next.