Hi community,
atm I’m trying to get my head wrap around collab filtering. So my first goal is to build a recommender on the MovieLeans dataset.
My current problem is that every recommendation gives me basicly the top n bester rated movies ever:
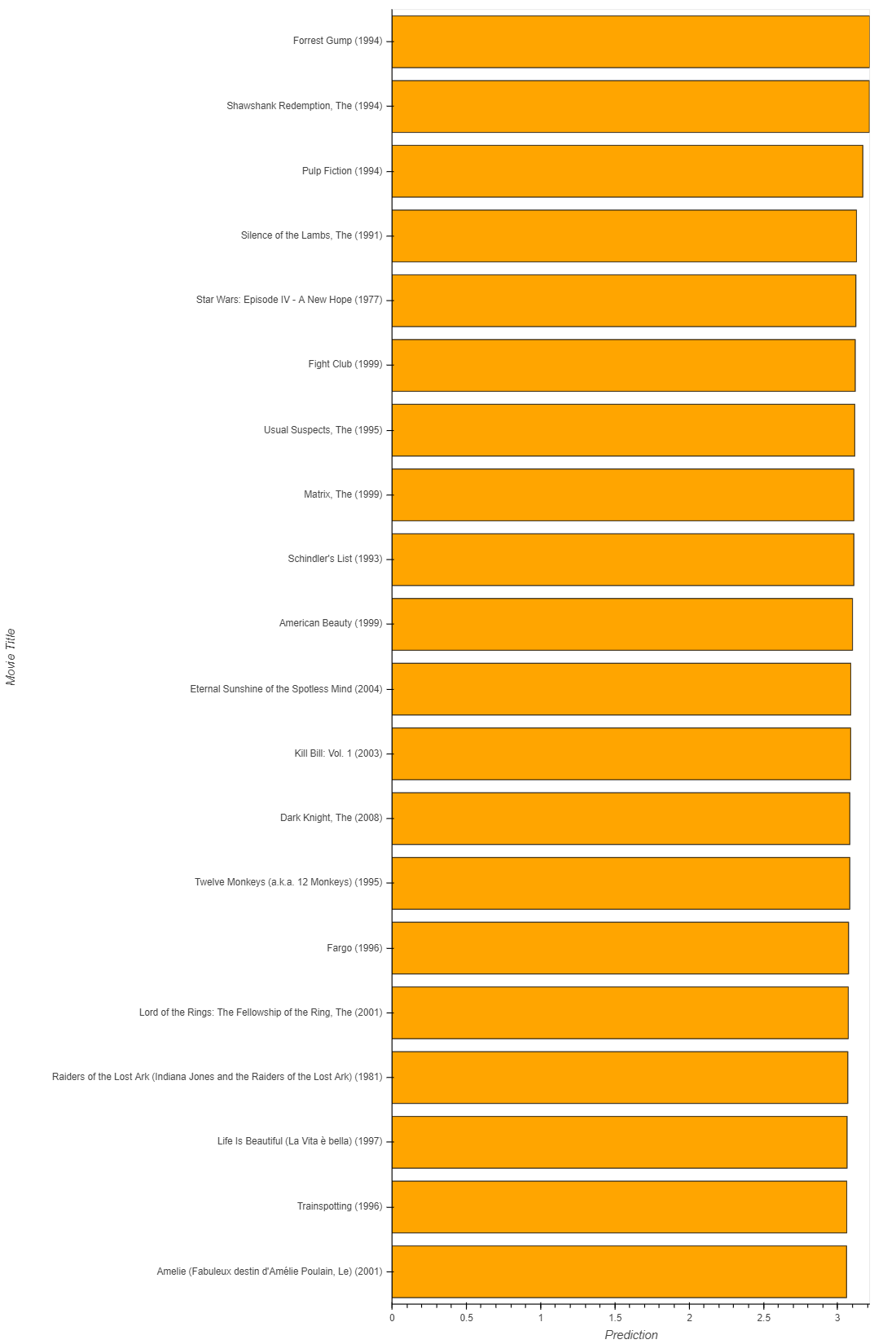
I guess the reason for that lies in the unbalanced dataset:
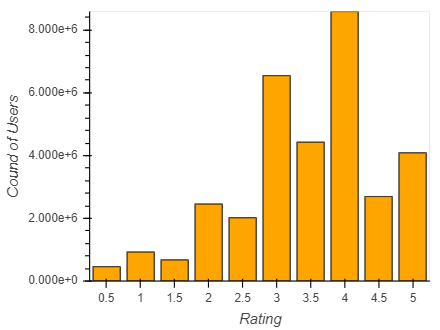
…So i have to oversample my data. In order to don’t corrupt my validation dataset, I have to do the oversampling after the train/valid-split.
Any advice how I can do this?
Best,
Colin