Hi I am having an issue with a project that I am working on. I am creating a model to predict the best search pattern based on a particular flight path.
The problem that I am hitting is that no matter how much data I give, or what features I change I seem to be getting the same results every time I train.
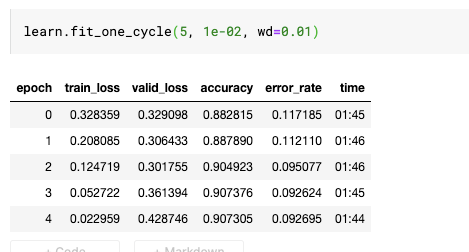
Firstly the model improves over 2 epochs (sometimes 3)
Then the model heavily overtrains from 2 epochs onwards with the training loss reducing rapidly and the validation loss increasing rapidly.
I have tried variations of learning rate and weight decay but I seem to always get the same results.
Here is an example of 5 epochs:
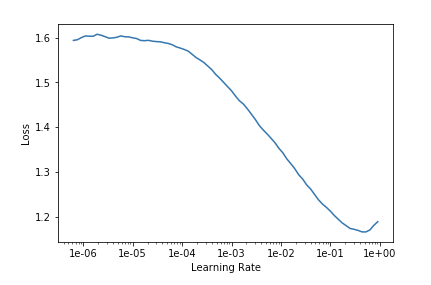
This is the lr_find
In this example I am using approx 820,000 data points but I have done the same tests with about 2.4 million with the same results.
Your model might be too big. Even though that might seem like loads of train data your model might still be able to remember it instead of predicting it. So I would try making the model smaller and also try things like batchnorm/dropout… to reduce the model’s ability to remember the data and to encourage
predicting instead.
Your data might also have something to do with it. Maybe your validation set is somehow different from the training set. But you did say you tried more data… did you use the same validation set when you changed how much data you used?
I tried to incorporate some of the advice from the Leslie Smith article on hyper parameters and changing the weight decay as well as the batch size seemed to improve the model.
I think I was expecting that 10 + epochs would be normal but I think you may be right that the model is not big enough and so over time it is remembering instead of predicting. It turned out that 3 epochs were enough to get a good output without the validation loss going through the roof.
I still have the problem of poor testing, but it’s likely the predictions are only good for predicting in a close time range. The model is predicting the best routes for flights and so it seems this changes regularly.
Hi, @mcclomitz
I seem to have a similar problem: tab data, improvement for 2-3 epochs then deterioration after that.
Did you see any positive results by changing the network size or depth?
Thanks.
Unfortunately not. Changing the network size did not make a huge difference.
I palyed round with different batch sizes, learning rates, momentum and weight decays and found something that worked over 3 epochs but that was the absolute maximum, anywhere after that and I would start to lose accuracy.
I have had similar problems with tabular data before. Here are some things to try:
Try different amounts of dropout.
Try using the early stopping callback or the save model callback (https://docs.fast.ai/callbacks.html) to save the model before it starts going the wrong way. Then try training a few more epochs at a reduced learning rate. Doing this 3 or 4 times has squeezed more performance out, in my experience.
I suspect that tabular datasets are just so small compared to things like computer vision that you really can’t train all that long and expect consistent improvement. They’re just easy to train.