Thanks. I saw the images in their paper but lacked the insight to check their github account!
How do you define Structured Data?
Data in well known given format?
Hi Yannet. Thanks for taking time to answer our questions. I have the following questions regarding previous lectures:
- In Lecture 4, when we use proc_df to split into train and validation sets, we have a mapper object containing mean and variance of the train set. The documentation says it will be used on the validation set when try the model. Why is this better than, say, using the mean and variance of overall data or using different means and variances for train and validation sets?
- In Lecture 4, we constructed a language model before doing sentiment analysis. We tried predicting the next words of the language model to check how good it is. Is there a more objective way to measure performance of a language model?
- This might not have come up in the lectures directly, but embedding layers return vectors as an output. Are word vectors such as GloVe trained by using embedding layers also? If so, what are the input and the target?
Thank you.
Q: “In Lecture 4, we constructed a language model before doing sentiment analysis. We tried predicting the next words of the language model to check how good it is. Is there a more objective way to measure performance of a language model?”
Look at perplexity in that lecture
Q: This might not have come up in the lectures directly, but embedding layers return vectors as an output. Are word vectors such as GloVe trained by using embedding layers also? If so, what are the input and the target?
Glove is trained by minimizing the equation in page 13/30 of this presentation. You compute a co-occurrency matrix by looking at words that occur nearby (2 to 3 words away). The Glove model is much more simple than the model Jeremy is learning which is an RNN.
http://llcao.net/cu-deeplearning15/presentation/nn-pres.pdf
Here is the lecture:
1 Like
But embeddings are just one-hot encodings - they’re simply a computational performance trick which gives the same result?.. And aren’t they easier than one-hot encodings, since you don’t have to encode anything?
1 Like
I was thinking these embeddings should mean something and can be used to understand which users/movies are similar to each other. But after I looked at lesson 5 notebook I see just a cloud of weights in embedding matrixes: no structure, no clusters visible. Have anybody used somehow these embeddings for clustering/segmentation ?
Take a look at the section ‘Analyze Results’ of this notebook from part 1 v1, maybe this will be of help 
I think you might also want to look at UMAP - sounds like a great use case to experiment with it.
1 Like
Thanks radek. Because of this notebook I have this feeling that embeddings should mean something.
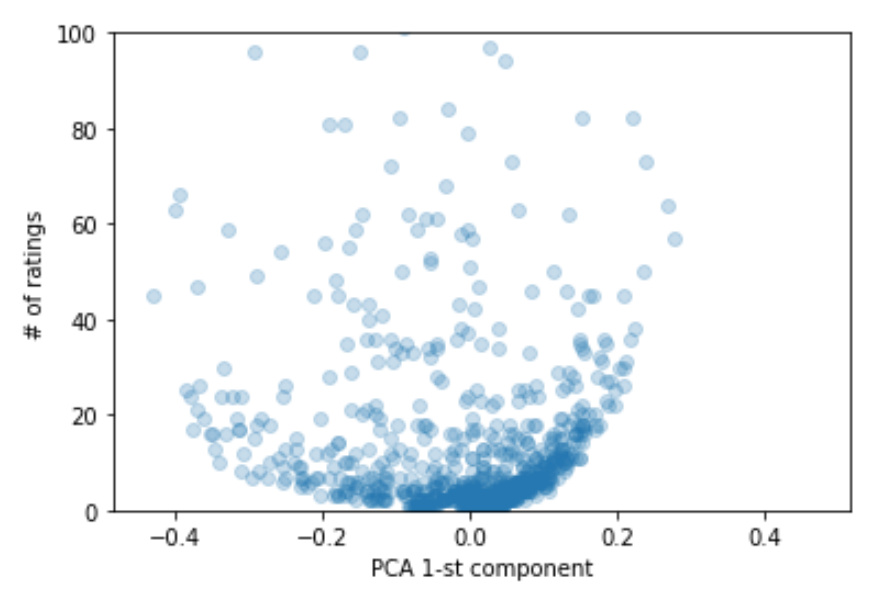
Now I think I am starting to get it. There are 9K movies being rated and only 50 were plotted. These 50 have the highest/lowest score which means they were significantly different from others. I have two assumptions I am going to check:
- I think if we plot 500 movies we want see any structure
- these top 50 movies have high number of ratings - i think only in this case embeddings really work. 1 movies - 1 rating - no need for embeddings.
Trying to wrap my mind around your statement that embeddings are OHE for some days already… and still don’t get it. I mean… even if only one dimension of embeddings size, still you would have OHE + weights…
Wouldn’t the conceptual comparison be more to a likelihood encoding (with embedding of one dimension), and a <insert here new name for possibly new concept, non linear “likelihood, or y aware, or impact”, encoding> for >1 embeddings size?
@sermakarevich, even if you only have one rating of a user that rating is giving you info about what he likes/dislikes. (Say its a romantic movie and he rated with 5 stars). You only need one rating to guess things about that user, in that case that possibly doesnt hate romatic movies. And the concept of “latent factors” implies that they mean something (other question is that you can guess the meaning  )
)
1 Like
Thanks for keeping the conversation @miguel_perez. I would mention that you do not have this “romantic movie” marker in your users-movies-ratings dataset. This marker your are trying to learn with embeddings and extracting “latent” factors, right?
In lesson 5 notebook there are genres in a separate file, but
- we do not use it
- there are typically multiple genres per movie
Adventure|Animation|Children|Comedy|Fantasy- how good a prediction can be in this case?
What I am trying to do is to cluster based on latent factors. And what I have found is that these latent factors become meaningful and more accurate when you have a lot of ratings. If you have 1 rating per user-movie these latent factors are just random as at the weight initialisation stage. CF just does not have to change them as there is nothing to learn.
Its a very interesting topic, yes, you dont have those kind of markers, of course. But the way I think about lattent factors is that they find (through SGD) some meaningful aspects of the movies. This can sometimes (only sometimes) be mapped to human-readable aspects, like my silly example of “romantic” factor.
What I meant is that this factors meaning is easier to be though of that way (its also the way Andres N.G. approaches de topic in his ML course, saying something like…“if we only could know what this aspects are -accion, romantic, length of movie, good music, whatever…- , if we only knew,… but we dont’t, so lets make SGD learn them for us”.
1 Like
Lets consider this theoretical example.
You have matrix1 5x5 where 5 users rated 5 movies. Also you have matrix 2 where other 5 users rated other 5 movies. No intersection between these matrixes but matrix 1 == matrix2 in terms of ratings even though they are unrelated.
No lets join these two matrixes into matrix 10x10 which has 50% density (no ratings for users from matrix 1 and movies from matrix 2 and visa versa). Lets initialise exactly the same weights for each movie in movies and for each user in users. Lets build a model and I bet we got the same latent factors for unrelated users rated unrelated movies similarly. Does this mean users are similar? - no. Does this mean movies are similar? - no. What happened? These latent factors are meaningless for unrelated ratings. The higher intersection of users/movies/ratings you have, the better latent factors you get. Unrelated rankings happens when low-active users ranks not popular movies.
2 Likes
Your point is very good, and also I would say that it is correct. That said, I think that it misses something:
I completely agree that the more interconections the more meaningful the factors, but, taking your example to a mental experiment (not real, but hope useful). Imagine we live in a world where some kind of movies and only some kind of them, ok, lets say action movies will give 1.000 dollars for every person that makes a positive rating.
In that world (lets guess) highest rated movies will be action movies. In your example, if the “ground truth” of ratings includes that action movies are the top rated both unrelated group of persons/movies will learn as the main factor the “action-ness” of the movie. So I think even in that case there would be a shared latent factor.
I think this also can happen to some extent in real examples. Anyway, as far as I know, your critic to matrix factorizacion for recommender systems is THE big critic , that is, they are limited and damaged by sparsity, and less useful for users with less ratings (and not useful at all for users with 0 ratings)
The bias term makes collaborative filtering useful for users with 0 ratings If you are to recommend someone a movie, even if you do not know anything about their preferences, better suggest them a good one that many other people agree to be interesting!
1 Like
@radek yeah, this its definitely your kind of mental playground! 
Thanks for the hint, I had completely overlooked that huge point! 
1 Like
I don’t think this is 100%accurate and I think this is what @miguel_perez was also getting at.
In your small example that likely is correct, but I suspect that the more data and the bigger our model grows, the less clear the situation becomes. Meaning, even if we have perfectly unrelated movie / user groups, still the meaning of latent factors will be to some extent parametrized by the model.
If we assume that there are some tastes people share globally (some like old / romantic movies, others action movies / w sfx) and that those relationships are distinct enough among themselves then if our model will be trained on large enough datasets, I think it might be imposing latent factor 1 to mean this and latent factor 2 to mean that across groups.
Say there are 3 latent factors and each groups of people (as they share tastes) combine latent factor A + B to produce score (one taste) and latent factor B * C to produce score for people with different taste - and only these two relationships exist. The I suspect that with enough data - assuming those tastes are universal across groups and with model of just right capacity, our model will learn to assign A, B, and C features to same latent factors, hence they will share meaning across disjoint groups.
Of course, I am not sure if this is the case though would be fun to try this
2 Likes
I think we are on the same page. Probably I had too high expectations about latent factors. They work, work well, but they need some minimal density level (art). After I increased density from 0.3 to 2.5% by filtering out user/movies with low number of ratings (in my case sites/ad campaigns), I saw the MATRIX:
left side - very good sites for every campaign
right side - very bad sites for every camapign
2 Likes
It’s not a conceptual comparison, it’s a literal identity. They are actually the exact same thing: OHE * weight matrix == embedding. Try a small example in a spreadsheet or on paper and I think it’ll be clear. If so - tell us what you learn! If not - please ask some more!
2 Likes