Hi I am new to fastai. And I found developement using fastai can be really fast  , but I also found, in my opinion, data loading procedure may be not flexible enough and not that intuitive.
, but I also found, in my opinion, data loading procedure may be not flexible enough and not that intuitive. 
I also make a novel proposition, which I think might have a chance to be literally 1. customizable to any data loading problem, and make anybody 2. understand data loading from head to toes within one single step and be able to customize it. 
Problem encountered: use Transformer Decoder to do Laguage Model
(you might can skip to proposition below if you are not familiar with or interested in the input of lagugale model problem)
data loading procedure in this setting is special, and in my knowledge it should be like this.
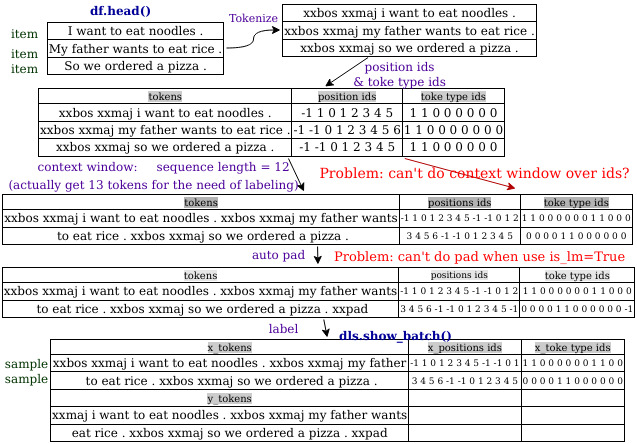
Problem Points
-
Although there is a special dataloader
LMDataLoaderin fastai2 to collect items(texts) into sample, but it is fixed and won’t take care of positon and token type ids.
-> transform pipeline can’t let us customize how to turn items into one sample.
(other example of sample from multiple items might be like mix two images (items) into one image as an sample. -
For a newbie like me, the logic of data loading process from dataframe/files to
x_batchandy_batchseems like scattered over source codes. It’s hard to understand when where splitter, labeling,… applied and what variables they can see.
-> may want a file or a function to see the whole data loading logic, so be able to know where and how customize it. -
dataloaders only includes train and val data when created, we have to load items by ourself and call
test_dl, why don’t we include test set at the time of creating dataloaders and have a function likelearn.test()** to validate test set?**
Novel Proposition: data loading callback system
what I think the data loading system should be is a refactoring for all data loading problems, and can customize to literally any you want. (just like callback system for training loop).
Below is a rough code example.
( **self means passing all of the instance’s attributes by their names along)
def dataloading(self, split_func, after_split, get_items_func, ...):
split_func(**self); after_split(**self)
# get [self.train_items, self.val_items, self.test_items]
get_items_func(**self); after_get_items(**self)
# g et [se lf.train_items_iter,se lf.val_items_iter, self.test_items_iter]
for self.item in self.train_items_iter: after_load_item(self)
# get self.item (e.g. path to a file/files )
read_item_func(**self); after_read_item(**self)
# get self.images (e.g. [PILImage_car, PILImage_mask] )
process_raw_func(**self); after_process_raw(**self)
# e.g. random crop augmentation
not_enough = make_sample_func(**self)
if not_enough: continue
# e.g. one sample = image that mixes image 1 crop and image 2 crop
# self.buffer = image 1 crop, if haven't collected enough materials to mask a sample. self.buffer = None, otherwise
# get self.mixed_images
after_maks_sample_func(**self)
get_x_func(**self); after_get_x(**self)
get_y_func(**self); after_get_y(**self)
numericalize(**self); after_numericalize(**self)
# turn category or text ... into numbers
tensorize(**self); after_tensorize(**self)
add_to_batch(**self); after_add_to_batch(**self)
yield self.batch
To customize data loading, just pass the function that you want to customize, so for a laguage model data loading from data frame, it might be sth like this
def lm_data_loading(...):
data_loading(
# df.head()
split_func = partial(col_split, 'dataset?', 'train', 'valid', 'test'),
# ---- text --- dataset? ----
# -- Hellow world --- train ------
# -- hot pancake --- valid ------
# -- cold water --- test -------
process_raw_func = tokenizer.tokenize,
after_process_raw = create_pos_and_type_ids,
make_sample_func = partial(context_window, seq_length=30, 'tokens', 'pos_ids', 'type_ids'),
# do context window on self.tokens, self.pos_ids, self.type_ids
get_x = partial([:-1], 'tokens', 'pos_ids', 'type_ids'),
# self.x = {'tokens': self.tokens[:-1], 'pos_ids': self.pos_ids[:-1], ...}
get_y = parrtial( [1:] , "tokens" ),
# self.y = {'tokens': self.tokens[1:]}
numericalize=tokenizer.vocab.encode
...
)
(we can also create a text_data_loading for every text problem first)
Data Flow and interface
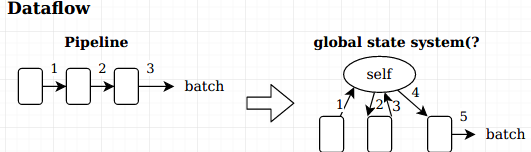
dataflow is different from original transformation pipeline, stages exchange data with storage across stages.
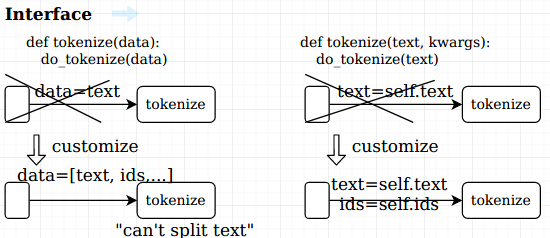
make every piece of data directly an attribute of self, and pass **self (pass every attributes of self by their names). make sure every stage can get data they want no matter how overall data changes.
Pros
- every stage can use data created from any previous stages
- stages can use data from previous runs (by storing it in self for next run), which might helpful to iteratively create context window and other situations.
-
know what the stage needs by looking into its function arguments, (Originally it is only an argument
orepresent the data pipelined, and don’t know what it is) so that we can correctly customize its previous stages -
easier to understance data loading process, just pass
set_traceto everyafter_<stage>, students can create a concrete understanding of what’s happening in the data loading. and become able to customize it. -
clear single function
dataloadingthat exlains every stages of data loading, don’t have to look to files and functions to know how exactly fastai make files/dataframes into batchs
Conclude
Would you guys found it easier to customize and understand? Share your thoughts and push the thread up.
Or you found current fastai2 can easily solve the laguage-model-by-transfomrer-decoder data loading problem, pleas help me out, I havn’t figure out how to do it. 