Hey guys! Excited to introduce and announce a new widget for Colab-users! (I will port this over to ipywidgets soon) I set myself a challenge to learn how to use Colab’s new widgets, as we still can’t use ImageCleaner (my next tackle). One related issue on the forum was a discussion about finding the images that two particular classes. As such, I made a widget that will show what two particular classes were missed in an image class!
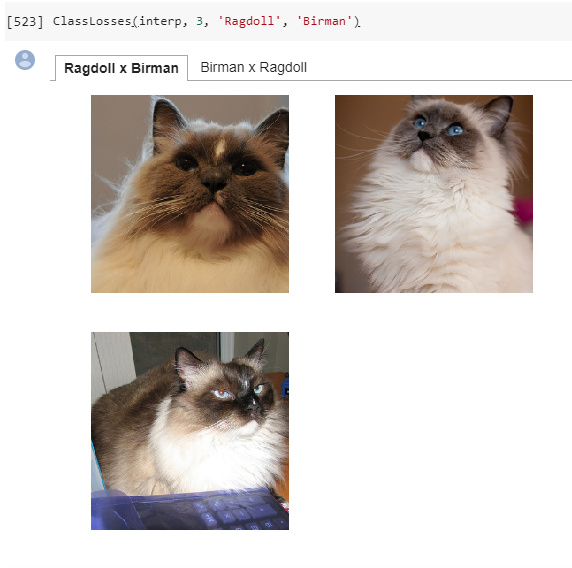
Example use, the pet’s notebook.
We input in our ClassificationInterpretation object, the number of photos we want to see, along with two classes.
Here we have two tabs that will show us Ragdoll when it was actually a Birman, and the other shows us the vice-versa! These images are sorted as they are found in the top_losses, so the most wrong will be your first image!
Current next plans:
Get it working on non-colab
Support more than 2 classes
ImageCleaner for Colab
Let me know how it goes, and if anyone finds any problems, any suggestions for improvement!!!
Update x2, Support for Tabular Models!: * Currently only available for one class combination
What does it do?
The program will go through your validation set and report back for a particular combination the distribution of your data. The goal of this was to be able to justifiably say which aspects of certain variables were leading to poor model performance and what our outliers were composed of. If I can figure out getting tabs of tabs working then multiple combinations can be ported.
How do I use it?
The plugin will be able to tell automatically which type of data we are dealing with, so now the function call for both tabular and images is simply:
ClassLosses(interp, myClasses)
When we deal with images now, you will be prompted to input a k value
Here is an example of the output from tabular data for both categorical and continuous variables:
Update (again)
Multi-combination support is now done. My workaround was to just plot those distributions in the tab along with a title specifying which graph’s (combination’s) distribution we are looking at!
Edit: Last update (hopefully):
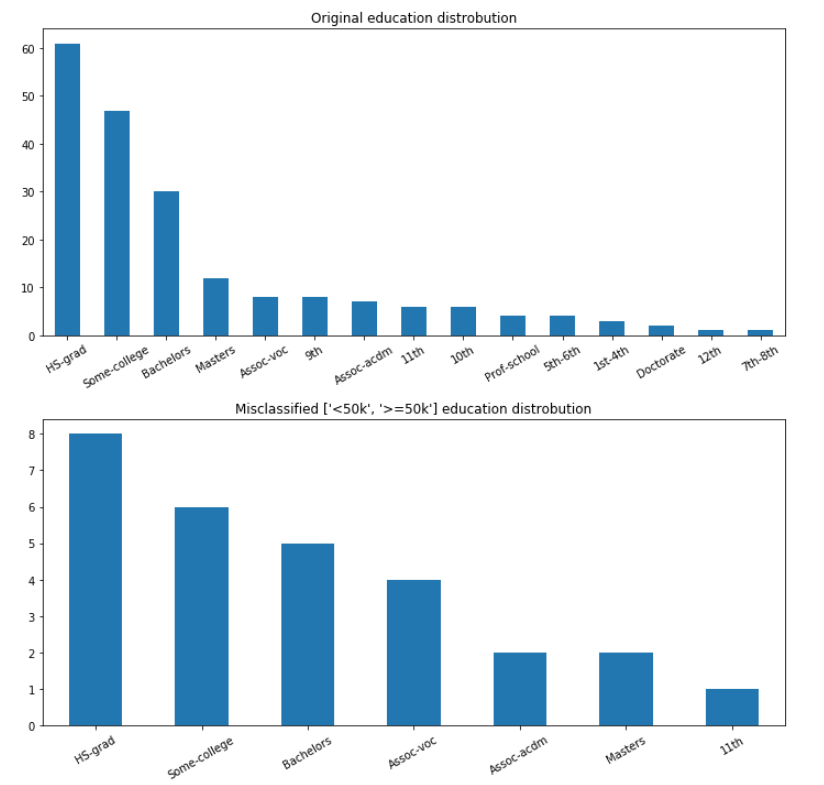
Changed the layout quite a bit. Now along with multi-class results for tabular, it will also show the original distribution of the data so you can run a proper comparison.
On images, along with showing what was missed I also show the filenames too! BIG thanks to @haverstind for the assistance there!!!
I’m pretty content with the product that it is, only thing that may change is optionally sending in a set combination list so we can review just those squares.
Wasn’t content. New way to pass in an ordered list of combinations to try:
ClassLosses(interp, cl, is_ordered=True)
Here we assume cl is a list of tuples in the order of (actual, prediction) eg:
There is a lot that I’ve changed and modified here. I’m working on porting it to the ipywidgets, it’s not as simple as I would have hoped but I would like to try to get this to into our main library so I’m doing my best to get this done. In all honesty, seeing this has helped me understand my tabular model’s behaviors and trends more than I had realized it would have. For instance, take the ADULTs notebook. If we look at Education:
We can pass in our ordered_list, cut_off is there so if you have categorical data with hundreds of categories, we can skip them as that graph may not be much use, var_list is there if you want to look at specific variable combinations. The very last step I want to try to do is export this all as a pdf optionally, and have it as a pretty set of graphs for further analysis later. But other than that I can’t think of anything else I would want to add or change. I’ll get started on the ipywidgets soon, but if you want to use this in google colaboratory I’d recommend the repo for absolute compatibility.