I work in consumer credit where we deal with a lot of panel data, e.g., a customer’s payment history. Consequently, I will have customers with multiple and varying number of observations. I’m looking at exploring an LSTM architecture but having difficulty figuring out how the time series element of the data should be reshaped and padded to account for the varying lengths of the sequence for different customers. This would be a one step classification problem where we try to predict whether a customer defaults or not in the month following the end of the sequence.
For a given customer, if for example that customer had 25 observations because he took out an account 25 months ago we would have 24 sequences for that customer the shortest with 1 observation and the longest with 24 observations.
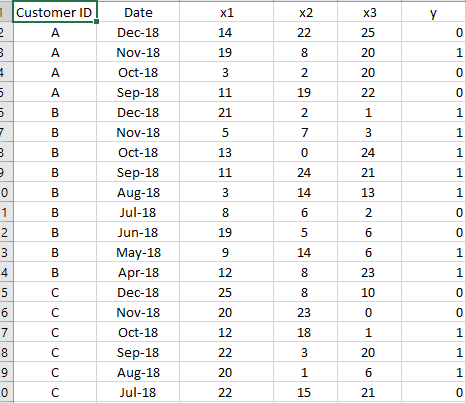
A dataset might look like this for your reference. Any examples
I am very interesting into this, as I have stumbled upon this problem several time, although it’s always been low on the priority list at my workplace (I am in a completely different sector). I probably would not use an LSTM for this, but it’s very gut based.
I am a bit confused by the dataset though: it looks like (for example) customer A defaulted in Dec 2018? (as the second row would suggest).
One thing to attempt could be: instead of raw “date” field, use the difference in dates between “date” and the date when the prediction is made and use a tabular learner
Sorry this was just for illustration, instead of defaulted, let’s say the borrower missed a payment. So in this example we would say that y=1 for Customer A in November 2018 means he missed his payment in December 2018 but y = 0 for December 2018 means he missed his payment for January 2019 if that makes sense? I hear what you’re saying. On this type of problem I would normally apply some rolling aggregations for each customer to capture the time series element and treat each loan month observation as a single sample (we have millions of rows of data and hundreds of thousands of customers so it’s usually not a problem to a loan month observation as if it were an independent sample). I wanted to see if anyone had any success applying a sequence model to this kind of problem is you can view the customer’s history as a sequence.
Hi Raed, sorry I missed this. Ultimately we just used a feedforward network and the time element of the data was summarised using rolling aggregations e.g., taking the the max, mean number of payments/made missed over some specified list of periods.
For validation we ensured that no account number could be in both train and test to prevent information leakage.
This was built as a challenger model. LightGBM outperformed the neural network by about 1.5% on AUC.