I don’t know if this will help you, but if you look at this example: https://www.kaggle.com/nikkisharma536/fastai-toxic
At the bottom there is a table of predictions, you could group them based on your different categories, and return the one with the highest prediction value per group. I am thinking that would be the easiest way.
When we did it we trained different classifiers, and we trained and ran the prediction in a loop, my question for you is if you really need to do it as a multi-label classification problem. I think you can get a better understanding by creating 10 different models.
If you are primarily interested in classifying based on a combinations of properties then you can combine features and treat them as 0 = not all present, 1 = all present.
Why do you think you will get more accuracy with different models? Wouldn’t you get the same accuracy with one model, where you just ignore predictions that aren’t relevant, as someone suggested?
There is another way if I get what you are trying to accomplish. Using more labels inadvertently means there are more errors possible within the model. Here is an example I have been working on that could relate to what you want. This may point you in the right direction.
I have about 92 different overall labels and each of those 92 labels have about 5 sub labels. The data consisted of 92 folders each with their corresponding labels in this case are numbers corresponding to what I was working on. So for example folder 1 would be ‘000024463’, folder 2 ‘000024464’…etc (you can really set this to what is relevant to you)
I train the model and then test the model on an image (like normal):
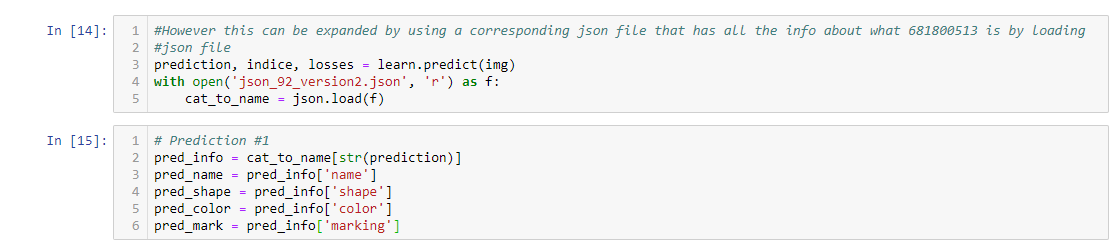
Rightly, I get a prediction that corresponds to the label - in this case a number. I then load a json file (this file has all the additional characteristics of the images in each folder - in your case the json file will contain the length, color type etc) which corresponds to this number.
Load the file as before but also load the json file and note the additional info in the file
Thanks Amrit,
if i understand well, you predict a features A and you got all differents information about A
it’s not exactly what i’m looking for.
I’ve A-1 A-2 or A-3, so if i predict A, I’ve to predict also 1 or 2 or 3