I must be missing something, and have spent a good few hours trying to work this out.
Using: 1.0.39.dev0
I have a TabularDataBunch created like this:
data = TabularDataBunch.from_df(path, df=df, dep_var=dep_var, valid_idx=valid_idx, procs=procs, cat_names=cat_vars, cont_names=cont_vars, test_df=df_test)
and a learner created as per below:
learn = tabular_learner(data, layers=[1000,500], ps=[0.001,0.01], emb_drop=0.04, metrics=accuracy)
I can create a single prediction ok using:
learn.predict(df_test.iloc[0])
Category the_predicted_category,
tensor(249),
tensor([2.6166e-04, 7.0190e-05, 1.6028e-05, 5.5844e-06, 1.7006e-03, 1.3622e-04,
4.4630e-04, 5.3242e-05, 5.2404e-06, 8.1808e-04, 1.8185e-05...
- however I want to predict on the entire test set and get the category (ie ‘the_predicted_category’ as above for each row in the test dataset.
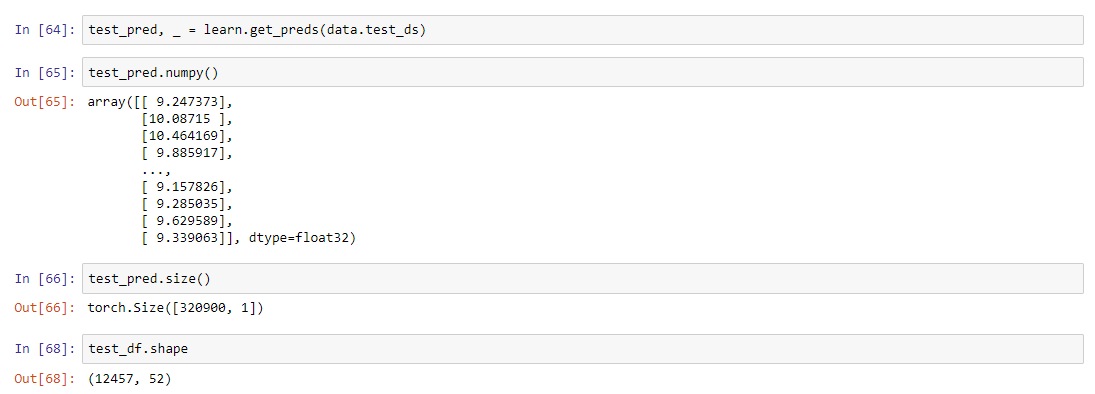
I can get the predictions like this:
preds, y = learn.get_preds(DatasetType.Test)
which returns:
tensor([9.1703e-08, 2.5174e-07, 1.0606e-07, 3.4502e-08, 3.1051e-07, 4.4129e-07,
1.0235e-06, 2.3513e-07, 3.2420e-08, 6.2728e-07, 3.2848e-07, 7.2376e-07,
4.3272e-07, 4.3480e-07, 7.6543e-07, 4.0239e-07, 1.6350e-07, 2.8251e-07,
3.4620e-07, 2.1245e-07, 1.3313e-07, 4.1516e-07...
Then from the index of the most likely in the tensor above, how do I get get the actual class it corresponds to?
Things I have tried:
My predicted tensor has dimension torch.Size([632])
If I get a CategoryList from the test dataset:
data.test_ds.y
It has a length of 8 and is non-unique - I presume this is giving me a batch of y data (same for data.test_dl.dataset.y)
Then if I look at:
data.train_ds.classes
the dep_var that I want to reconstruct the category name out of is not in the classes, even though it was included:
df = train_df[cat_vars + cont_vars + [dep_var]].copy()
Then when I look at TabularDataBunch.from_df() during execution:
src = (TabularList.from_df(df, path=path, cat_names=cat_names, cont_names=cont_names, procs=procs)
.split_by_idx(valid_idx)
.label_from_df(cols=dep_var, classes=classes))
data.train_dl.c
returns 632 - which looks to be the number of categories in my dep_var…
Testing the assumption that fastai just uses something similar to below to generate the categories from which test predictions are made (I couldnt find anything like this in the code), and then indexing into ‘categories_to_index_into’ to get the predicted category :
categories_to_index_into=set(train_df['Target_Column'].values)
does not give the same predicted categories as per:
for idx, row in df_test.iterrows():
pred = learn.predict(row)
Iterating though the entire dataframe row by row is unfeasible as it contains several million rows. Has anyone managed to work this out?