First of all I would like to say thank you a lot to Jeremy and all fastai contributors for all the great resources that you have created and gathered here. I’ve been working in ML projects for some time now and I want to open to discussion with all of you an issue that I have frequently see when starting a new project.
I’ve been recently more involved on the early stages of ML projects (specifically for ML application on industry manufacturing processes) and I find many companies on early stages of digitization with a few or non data at all, so domain expert knowledge gathering and assumptions definition are the key to start acquiring the correct data and solve the problem. Here the problem is not to find the most relevant features on a vast dataset or deal with them on many ways, but to decide what data is important to start measuring. I’ve resorted to DMAIC (six sigma) methodologies to help me gather that domain expert knowledge, and I put great effort in research previous works on similar problems, but it is always hard to ensure the viability of each project and the key features to measure. I feel like I might be missing something, some great resources dealing with this previous stage of ML application, because it seems to me that many times it is the main obstacle to apply ML on industry due to the importance of the Return Of the Investment to unlock the projects.
Thank you very much in advance for your time and for any useful information you may share.
In my experience an important first first step is to be clear about the potential business value of solving the quality/productivity issue (i guess thats what we are talking about) irrespective of the technology that could be used to solve it. High value projects tend to get more ressources to succeed if there is a plausible solution or range of solutions.
Yes, I agree that measuring the potential impact (on economic terms) is a key. Thank you very much Kaspar.
But let’s think you already have find an economic opportunity and you want to make the most of it by applying ML. Usually ML challenges (such as those in kaggle) start with the data already selected and more or less processed to start applyng ML and data preparation/transformation techniques. However, the steps to choose this data and to deploy systems to start acquiring new inputs are not usually addressed in depth. Neither I have found recommendation about how to anticipate the viability of the solution at early steps. I suppose there is no magic wand, but I’m sure there should be best practices or methodologies to try to lower the risk during the first steps of a ML project definition.
@jeremy, do you have any insight on how this critical steps could be carried out?
I think the problem that you are trying to solve in a particular problem can help dictate what kind of data might be necessary to solve it. Trying to structure ML problems into categories of tasks will definitely help understand what kind of data is needed.
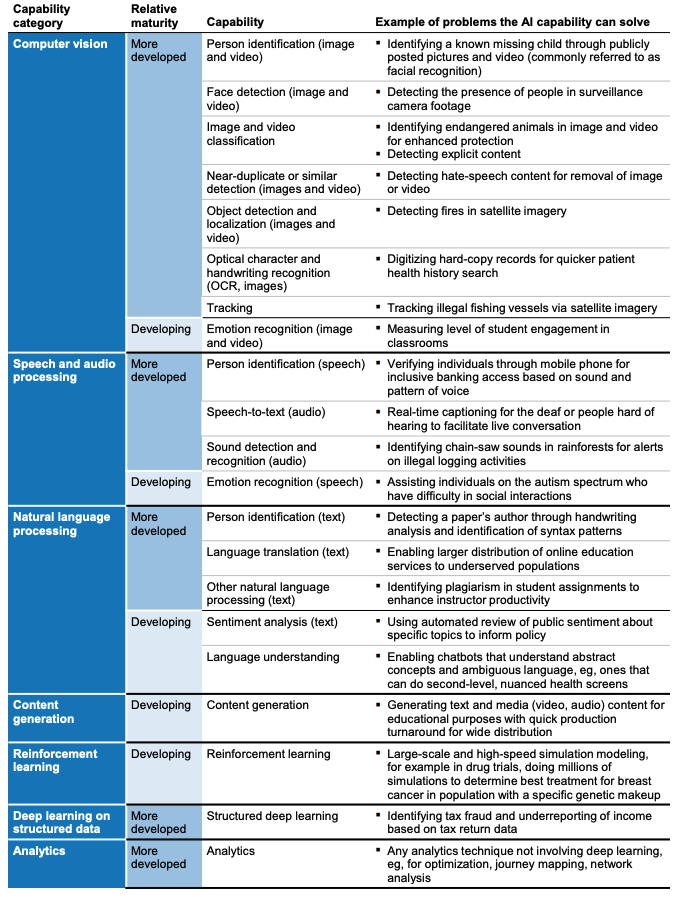
For example, I found this report by McKinsey really insightful. Specifically, on page 11 (in PDF report they list a range of tasks that AI is good at solving / making progress.
Then you just think about what of these tasks are needed to solve a particular problem in manufacturing and the task will dictate type of data that you need.