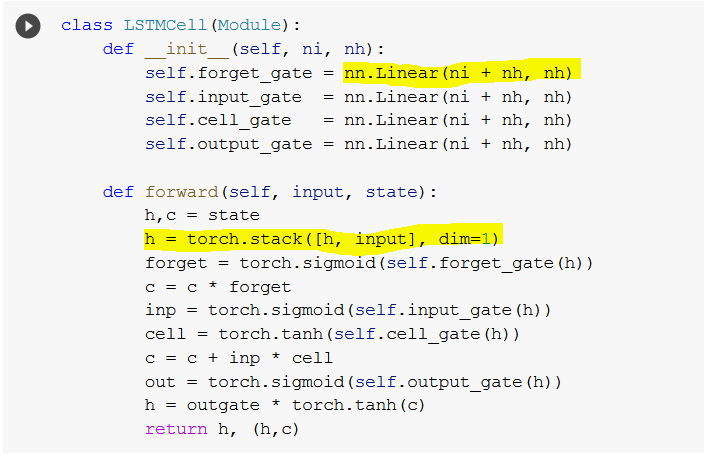
h is a torch.stack of the tensors h and input. h and input are both two dimensional tensors, so the resulting h should be three dimensional since stack adds a dimension. In contrast, torch.cat does not add a dimension.
self.forget_gate is also two dimensional. So how can the matrix multiplication in self.forget_gate(h) be possible? Are we not multiplying a three-dimensional tensor by a two-dimensional tensor?
In the refactored LSTM later in the notebook, I don’t see the same shape problem. What am I missing?