What’s “entity encoding”? I don’t see the term in the linked article.
Thought that was a type and corrected it!
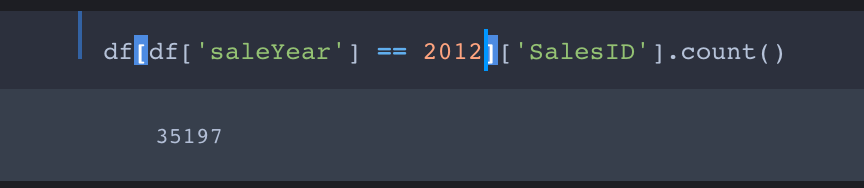
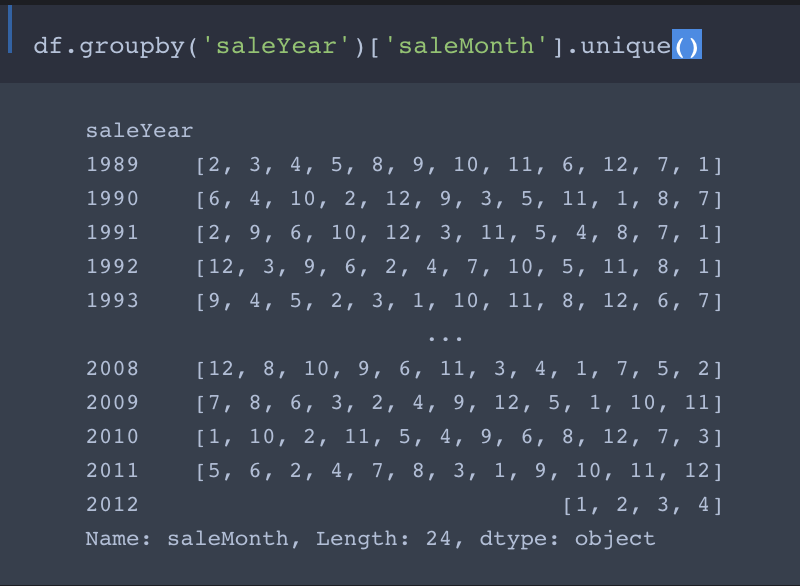
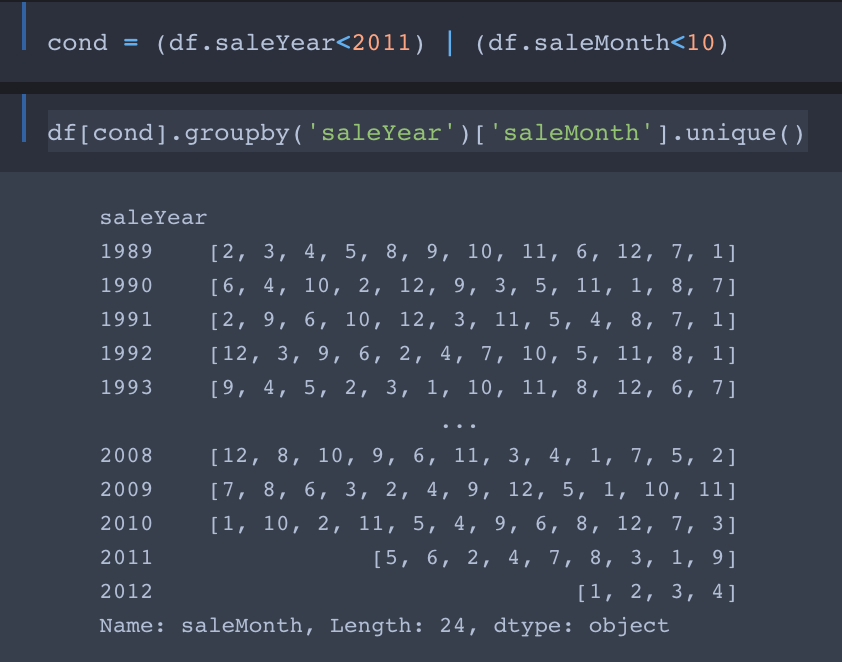
No, the use of | is actually intended. Here’s why:
We want the training set to contain all entries with saleYear up to September 2011 and the validation set to contain all entries from October 2011 forward.
So the first part of cond selects entries with saleYear of 2010 and earlier into the training set. The second part filters the entries with saleYear ranging from from Jan 2011 to Sept 2011 into the training set.
Comment: In my opinion this not a good way to do the filtering. As you may have noticed, it works only if there are no entries with saleYear later than 2011. If we were to add entries from the first three quarters of 2012 (or any later year) to the data, they would get (unintentionally) thrown into the training set!
A better, foolproof way to filter the data into the training and test sets is
cond = (df.saleYear<2011) | ( (df.saleMonth<10) & (df.saleYear==2011) ))
1 Like
3 Likes
Great catch @sylvaint!
With the corrected filtering algorithm, we should be able to get improved accuracy on the predicted sale prices!
Actually it does not help. Having more recent data in the training set skewed the results positively.
With the correct splits I get:
| Model | Updated r_mse | Previous r_mse |
|---|---|---|
| random forest | 0.24241 | 0.230631 |
| neural net | 0.263618 | 0.2258 |
| ensembling | 0.241996 | 0.22291 |
The results are not as good as with the erroneous splits. More importantly the neural net result is not as good as the random forest result which contradicts the book’s section conclusion for that dataset.
3 Likes
Well done, @sylvaint!
I was going to change my previous comment to predict that things would in fact get worse rather than better, but I see I’m too late.
So, I’ll explain why things got worse:
Performance on the corrected validation set becomes poorer than with the original validation set because of data leakage, which Jeremy also discusses in Chapter 9. Indeed, this case serves as an excellent example.
Before we corrected the filter for the training and validation sets, the model was able to (unintentionally) cheat by data snooping, i.e. by illegally incorporating into the training set some of the data from the later times (post-2010) which it is trying to predict. This is an example of data leakage So with the original training and validation split, the validation scores are artificially high due to cheating.
The corrected filter purges the training set of the illegal data points, which now become part of the validation set, as they should have been in the first place. Now, not only can’t the model cheat, but it has to predict on even more post-2010 data points, which is why the validation scores become worse!
2 Likes
What is the best way to extract the embeddings from the tabular_learner or TabularModel object?
If you want the weights you should be able to just do learn.model.embeds.weights
1 Like
A TabularLearner object has no property called weights. It does have a method parameters but that is a generator and I don’t know how to get the embeddings out of it.
If you check each embed IE learn.model.embeds[0] it has a .weight attribute. Also we’re dealing in raw PyTorch now 
That being said, if you do:
list(learn.model.embeds.parameters())
This also grabs it. IE I can do li = list(learn.model.embeds.parameters()) and if you check li[0].shape it’s the [10,6]
1 Like
Thanks Zachary. Figured it out. The weights are gotten for the k’th embedding by model.embeds[k].weights
But I’d forgotten that you can get all the values out of a generator by using the list method!
1 Like
I’m having a problem with the pre-processor Normalize when creating a TabularPandas object.
I’m running the notebook “09_tabular” in the fastbook repo, and I get this error when running the eighth cell under the section " Using a Neural Network":
procs_nn = [Categorify, FillMissing, Normalize]
to_nn = TabularPandas(df_nn_final, procs_nn, cat_nn, cont_nn,
splits=splits, y_names=dep_var)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-150-cd0965f9989a> in <module>
1 to_nn = TabularPandas(df_nn_final, procs_nn, cat_nn, cont_nn,
----> 2 y_names=dep_var, splits=splits)
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/tabular/core.py in __init__(self, df, procs, cat_names, cont_names, y_names, y_block, splits, do_setup, device, inplace, reduce_memory)
165 self.cat_names,self.cont_names,self.procs = L(cat_names),L(cont_names),Pipeline(procs)
166 self.split = len(df) if splits is None else len(splits[0])
--> 167 if do_setup: self.setup()
168
169 def new(self, df):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/tabular/core.py in setup(self)
176 def decode_row(self, row): return self.new(pd.DataFrame(row).T).decode().items.iloc[0]
177 def show(self, max_n=10, **kwargs): display_df(self.new(self.all_cols[:max_n]).decode().items)
--> 178 def setup(self): self.procs.setup(self)
179 def process(self): self.procs(self)
180 def loc(self): return self.items.loc
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py in setup(self, items, train_setup)
195 tfms = self.fs[:]
196 self.fs.clear()
--> 197 for t in tfms: self.add(t,items, train_setup)
198
199 def add(self,t, items=None, train_setup=False):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py in add(self, t, items, train_setup)
198
199 def add(self,t, items=None, train_setup=False):
--> 200 t.setup(items, train_setup)
201 self.fs.append(t)
202
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py in setup(self, items, train_setup)
76 def setup(self, items=None, train_setup=False):
77 train_setup = train_setup if self.train_setup is None else self.train_setup
---> 78 return self.setups(getattr(items, 'train', items) if train_setup else items)
79
80 def _call(self, fn, x, split_idx=None, **kwargs):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/dispatch.py in __call__(self, *args, **kwargs)
97 if not f: return args[0]
98 if self.inst is not None: f = MethodType(f, self.inst)
---> 99 return f(*args, **kwargs)
100
101 def __get__(self, inst, owner):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/tabular/core.py in setups(self, to)
276 self.means,self.stds = dict(getattr(to, 'train', to).conts.mean()),dict(getattr(to, 'train', to).conts.std(ddof=0)+1e-7)
277 self.store_attrs = 'means,stds'
--> 278 return self(to)
279
280 @Normalize
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py in __call__(self, x, **kwargs)
70 @property
71 def name(self): return getattr(self, '_name', _get_name(self))
---> 72 def __call__(self, x, **kwargs): return self._call('encodes', x, **kwargs)
73 def decode (self, x, **kwargs): return self._call('decodes', x, **kwargs)
74 def __repr__(self): return f'{self.name}:\nencodes: {self.encodes}decodes: {self.decodes}'
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py in _call(self, fn, x, split_idx, **kwargs)
80 def _call(self, fn, x, split_idx=None, **kwargs):
81 if split_idx!=self.split_idx and self.split_idx is not None: return x
---> 82 return self._do_call(getattr(self, fn), x, **kwargs)
83
84 def _do_call(self, f, x, **kwargs):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/transform.py in _do_call(self, f, x, **kwargs)
86 if f is None: return x
87 ret = f.returns_none(x) if hasattr(f,'returns_none') else None
---> 88 return retain_type(f(x, **kwargs), x, ret)
89 res = tuple(self._do_call(f, x_, **kwargs) for x_ in x)
90 return retain_type(res, x)
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastcore/dispatch.py in __call__(self, *args, **kwargs)
97 if not f: return args[0]
98 if self.inst is not None: f = MethodType(f, self.inst)
---> 99 return f(*args, **kwargs)
100
101 def __get__(self, inst, owner):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/fastai/tabular/core.py in encodes(self, to)
280 @Normalize
281 def encodes(self, to:Tabular):
--> 282 to.conts = (to.conts-self.means) / self.stds
283 return to
284
~/anaconda3/envs/fastai/lib/python3.7/site-packages/pandas/core/ops/__init__.py in f(self, other, axis, level, fill_value)
645 # TODO: why are we passing flex=True instead of flex=not special?
646 # 15 tests fail if we pass flex=not special instead
--> 647 self, other = _align_method_FRAME(self, other, axis, flex=True, level=level)
648
649 if isinstance(other, ABCDataFrame):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/pandas/core/ops/__init__.py in _align_method_FRAME(left, right, axis, flex, level)
501 elif is_list_like(right) and not isinstance(right, (ABCSeries, ABCDataFrame)):
502 # GH17901
--> 503 right = to_series(right)
504
505 if flex is not None and isinstance(right, ABCDataFrame):
~/anaconda3/envs/fastai/lib/python3.7/site-packages/pandas/core/ops/__init__.py in to_series(right)
464 if len(left.columns) != len(right):
465 raise ValueError(
--> 466 msg.format(req_len=len(left.columns), given_len=len(right))
467 )
468 right = left._constructor_sliced(right, index=left.columns)
ValueError: Unable to coerce to Series, length must be 1: given 0
However, if I remove Normalize from the pre-processing steps, the code runs without issue:
to_nn = TabularPandas(df_nn_final, procs=[Categorify, FillMissing], # removed Normalize from `procs`
cat_names = cat_nn, cont_names = cont_nn,
splits=splits, y_names=dep_var)
And the NN will also train without issue after removing the Normalize preprocessing. I also get results for learning rates and losses comparable to those in the repo’s notebook. My notebook is on the left, the right is from fastai’s GitHub repo:
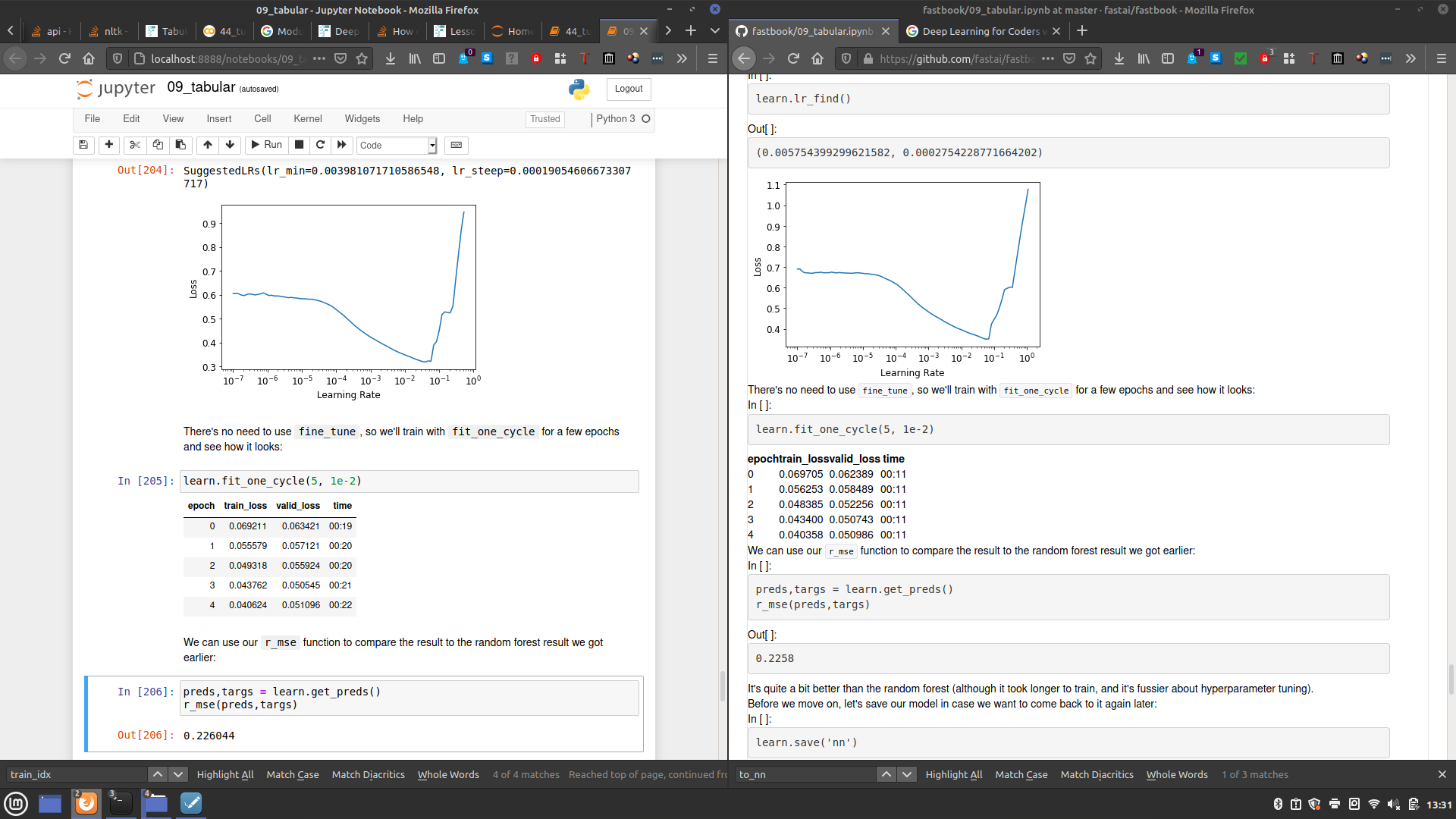
I’ve run this notebook on several machines (Windows/Ubuntu/Google Colab), and have had the exact same issue on every machine. I’m running fastai 2.0.6, pandas 1.1.1, and Python 3.7.7.
Has anyone else had this issue?
5 Likes
I’m having the same problem, but am getting a different error message, see image. In ptic TypeError: Object with dtype category cannot perform the numpy op subtract.
Yes, when I remove the Normalize argument the code runs.
How strange! Explanation would me much appreciated!
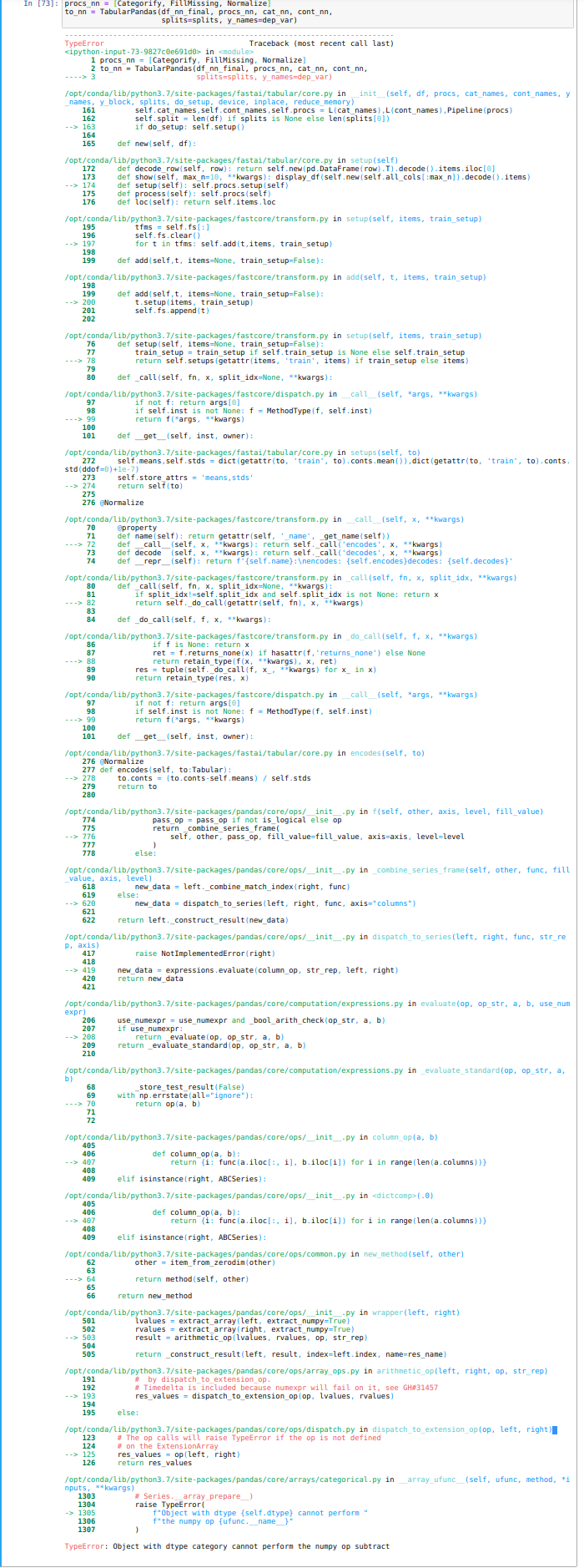
@Sturzgefahr @wlw If you inspect df_nn_final[cont_nn[0]] you’ll see that the dtype is “object”. When the dataframe was read in, Pandas wasn’t confident that the column contained integers, so assigned it a more general type. Fastai needs numeric types to perform the normalization. To fix this, modify df_nn_final such that the continuous variable is numeric:
df_nn_final = df_nn_final.astype({cont_nn[0]: 'int32'})
to_nn = TabularPandas(df_nn_final, procs_nn, cat_nn, cont_nn,
splits=splits, y_names=dep_var)
9 Likes
Thanks for the insight!
Could you please anyone help on how to resolve the following error?
cluster_columns(xs_imp)
ValueError Traceback (most recent call last)
in
----> 1 cluster_columns(xs_imp)
D:\Miniconda3\envs\fastai\lib\site-packages\fastbook_init_.py in cluster_columns(df, figsize, font_size)
70 z = hc.linkage(corr_condensed, method=‘average’)
71 fig = plt.figure(figsize=figsize)
—> 72 hc.dendrogram(z, labels=df.columns, orientation=‘left’, leaf_font_size=font_size)
73 plt.show()
74
D:\Miniconda3\envs\fastai\lib\site-packages\scipy\cluster\hierarchy.py in dendrogram(Z, p, truncate_mode, color_threshold, get_leaves, orientation, labels, count_sort, distance_sort, show_leaf_counts, no_plot, no_labels, leaf_font_size, leaf_rotation, leaf_label_func, show_contracted, link_color_func, ax, above_threshold_color)
3275 “‘bottom’, or ‘right’”)
3276
-> 3277 if labels and Z.shape[0] + 1 != len(labels):
3278 raise ValueError(“Dimensions of Z and labels must be consistent.”)
3279
D:\Miniconda3\envs\fastai\lib\site-packages\pandas\core\indexes\base.py in nonzero(self)
2413
2414 def nonzero(self):
-> 2415 raise ValueError(
2416 f"The truth value of a {type(self).name} is ambiguous. "
2417 “Use a.empty, a.bool(), a.item(), a.any() or a.all().”
ValueError: The truth value of a Index is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().