There is no hard and fast rule for the size of the embedding vector. This message posted earlier can help.
It depends on the type of categorical variable. How much impact it would have on the model’s behaviour for the predictions that you are trying to make ?
With one bias, the model results would be less accurate.
In the context of the User Movies Rating model explained by Jeremy for the Excel workbook, this article could help understand the real world intuition behind the user & movie embeddings which calculate the latent factors - https://medium.com/@MaheshNKhatri/collaborative-filtering-understanding-embeddings-in-user-movie-ratings-a4faa3975a41
1 Like
This link may help - https://towardsdatascience.com/how-to-select-the-right-evaluation-metric-for-machine-learning-models-part-1-regrression-metrics-3606e25beae0
1 Like
Yes, I had to download the ml-100k folder to that location and correct the path such that the following path was put into the folder:
new:
path=Config.data_path()/'movie_lens_sample'/'ml-100k'
old:
path=Config.data_path()/'ml-100k'
Then it showed up correctly for me.
@jeremy I noticed in the Excel workbook, in the first sheet, that in your formula for RMSE, your denominator uses COUNT of the input matrix (with the blank values), which doesn’t count these blank values. Could you explain why?
Why does he keep referring to the first (single-layer) MNIST model as being a logistic classifier, when there is no logistic function being applied? It’s just doing a single (linear) matrix multiplication.

Hi All,
Is there any rule or best practice in Deep learning to use the same activation
throughout the layers expected may be for the Ouput layer.
Eg, If I am using Relu in one layer, is there any rule or best practice to use Relu
throughtout the network, or I can use Tan or any other activation function.
Thanks and Regards,
Subho
Hello everybody,
As Jeremy suggested, I’m trying to code a MyLinear pytorch module. I think i’m pretty close but I got trouble to manage the batchsize dimension of the input.
Here’s my code :
class MyLinear(nn.Module):
def __init__(self, inFeatures, outFeatures, needBias):
super().__init__()
self.weight = nn.Parameter(torch.Tensor(outFeatures, inFeatures))
if needBias:
self.bias = nn.Parameter(torch.Tensor(outFeatures))
def forward(self, xb):
return xb.matmul(self.weight) + self.bias
And I get this error :
size mismatch, m1: [64 x 784], m2: [10 x 784] at /pytorch/aten/src/THC/generic/THCTensorMathBlas.cu:266
The only way I found to make it works was to cheat and get the code of torch.nn.functional:
def forward(self, xb):
return torch.addmm(torch.jit._unwrap_optional(self.bias), xb, self.weight.t())
Does anyone has a clearer implementation for the forward method ?
You should transpose your weight to generate a dot product of your matrix. You can also use @ instead of matmul.
import torch
import torch.nn as nn
import torch.nn.functional as F
class MyLinear(nn.Module):
def __init__(self, inFeatures, outFeatures, needBias):
super().__init__()
self.weight = nn.Parameter(torch.Tensor(outFeatures, inFeatures))
if needBias:
self.bias = nn.Parameter(torch.Tensor(outFeatures))
def forward(self, xb):
#return xb.matmul(torch.t(self.weight)) + self.bias
return xb@torch.t(self.weight) + self.bias
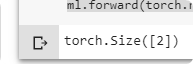
ml = MyLinear(33,2,True)
ml.forward(torch.rand(33)).shape
1 Like
would you please explain this formula …
Hi all, I’ve been trying to see if I can apply weight decay to the SGD function from lesson 2, but 've noticed that it’s actually worse when applying weight decay. What I’m doing is generating mini batches of 100 each and then applying them in a loop for SGD, outputting the
def update_normal(x, y, lr=1e-1):
y_hat = x@a
loss = mse(y, y_hat)
if t % 10 == 0: print(loss)
loss.backward()
with torch.no_grad():
a.sub_(lr * a.grad)
a.grad.zero_()
return loss.item()
def update_wd(x, y, lr=1e-1):
wd = 1e-3
w2 = 0.
y_hat = x@a
w2 += (a**2).sum()
loss = mse(y, y_hat) + w2 *wd
if t % 10 == 0: print(loss)
loss.backward()
with torch.no_grad():
a.sub_(lr * a.grad)
a.grad.zero_()
return loss.item()
n=100
x_new = torch.ones(n,100,2)
x_new[:,0:,0].uniform_(-1,1)
a = torch.tensor([3.,2])
y = x_new@a + torch.rand(n)
### WITHOUT WEIGHT DECAY
a = torch.tensor([-1.,1])
a = nn.Parameter(a); a
without_losses = []
for idx, x_vals in enumerate(x_new):
t = idx
loss_val = update_normal(x_vals, y[idx])
without_losses.append(loss_val)
Above is the modifications I’ve made, I’ve separated them into two functions just to make it clear of the difference. The only other modification (as mentioned) is making 100 batches with 100 samples each. I’ve not looped through the parameters like in the lesson 5 example because this isn’t using a pytorch model! Below are my results with weight decay added
#WITH WEIGHT DECAY
a = torch.tensor([-1.,1])
a = nn.Parameter(a); a
wd_losses = []
for idx, x_vals in enumerate(x_new):
t = idx
loss_val = update_wd(x_vals, y[idx])
losses.append(loss_val)
My output:
tensor(7.4193, grad_fn=<AddBackward0>)
tensor(1.4599, grad_fn=<AddBackward0>)
tensor(0.4672, grad_fn=<AddBackward0>)
tensor(0.1465, grad_fn=<AddBackward0>)
tensor(0.1061, grad_fn=<AddBackward0>)
tensor(0.0980, grad_fn=<AddBackward0>)
tensor(0.0918, grad_fn=<AddBackward0>)
tensor(0.0877, grad_fn=<AddBackward0>)
tensor(0.0898, grad_fn=<AddBackward0>)
tensor(0.0916, grad_fn=<AddBackward0>)
And without weight decay:
### WITHOUT
a = torch.tensor([-1.,1])
a = nn.Parameter(a); a
without_losses = []
for idx, x_vals in enumerate(x_new):
t = idx
loss_val = update_normal(x_vals, y[idx])
without_losses.append(loss_val)
My output when not using weight decay:
tensor(7.4173, grad_fn=<MeanBackward0>)
tensor(1.4525, grad_fn=<MeanBackward0>)
tensor(0.4554, grad_fn=<MeanBackward0>)
tensor(0.1328, grad_fn=<MeanBackward0>)
tensor(0.0916, grad_fn=<MeanBackward0>)
tensor(0.0830, grad_fn=<MeanBackward0>)
tensor(0.0767, grad_fn=<MeanBackward0>)
tensor(0.0733, grad_fn=<MeanBackward0>)
tensor(0.0749, grad_fn=<MeanBackward0>)
tensor(0.0760, grad_fn=<MeanBackward0>)
Why do I get (albeit slightly) worse results when weight decay is applied? Is this because the model in question (linear) is not complex at all, thus it is not helping? Or have I not applied weight decay correctly?
Can someone list some examples for when one would have to inherit nn.Module instead of using one of the default Learners?

There’s a file error, if you want to read in a csv the first argument of pd.read_csv needs to be the file path to that csv. ‘u.data’ and ‘u.item’ presumably are Python objects? You need to point that function to an actual .csv file, for example “my_data.csv”.
as of Jul. 28th 2019, probably it does not provide (sorry if it is wrong).
My workflow to use 100k data is the following:
- current environment:
– using Crestle.ai
– fastai ver. 1.0.55
– just have donegit pullatcourses/fast-ai/course-v3/
- I download the data from:
– http://files.grouplens.org/datasets/movielens/ml-100k.zip - Upload the zip from Jupyter notebook’s UI
– You can find Upload button on upper right of the screen - Open terminal from New -> Terminal
- Move directory to the place you uploaded the file (probably /home/crestle/fastai)
- Move ml-100k.zip file to /home/crestle/.fastai/data (note that ‘dot’ exist before ‘fastai’)
– use linux command: https://www.rapidtables.com/code/linux/mv.html - Navigate your directory to /home/crestle/.fastai/data with
cdcommand - Unzip the zip file with
unzip ml-100k.zip
This let me run all codes in less4-collab.ipynb.
(I am a very beginner for using linux, so there should be more efficient way…)
2 Likes
I’m looking at this snippet from the class notes for lesson 2, since i needed to review for lesson 5.
def update():
y_hat = x@a
loss = mse(y, y_hat)
if t % 10 == 0: print(loss)
loss.backward()
with torch.no_grad():
a.sub_(lr * a.grad) // this line!!!
a.grad.zero_()
What I’m not understanding is how does a.grad get populated. a is not passed into loss.backward() and I don’t see how it could reference it. If anyone has a suggestion on understanding this line, it would be appreciated.
Hey guys,
As Jeremy asked in the Lesson 5,
I just re-created the NN.linear class and Adam optimizer from scratch.
The only blurry part is the first weights update.
Since Adam relies on having previous update vectors to process the new updates, I used regular SGD for the first update.
But how is this normally done?
Of course feel free to criticize my code and the way I mad it work.
Here’s the notebook:
I’m not fully understanding it myself but from what I actually understood:
The parameters of the NN layers are matrices of weights and bias stored as Pytorch Tensors.
When a tensor is created there is a boolean parameter called ‘Requires_grad’.
Here comes the blurry part for me so take it with a grain of salt (I have to digg in the source code of autograd):
If ‘Requiers_grad’ is set to True, the tensors is created with an extra “grads matrix” of same size and empty.
Then, when you call “loss.backward()”, Pytorch is somehow able to go back to the formula that produced ‘Loss’ and find the tensors involved for which “requiers_grad=True”.
Pytorch then processes the partial derivative for each entry in the tensor and stores the result in the extra “grads matrix”.
So when you call ‘a.grad’ you are indeed only looking in this “grads matrix” attached to ‘a’.
Is that somehow clear?
2 Likes